Hvorfor får du 34 rader i csv-eksporten fra et vegkart-søk med 10 vegobjekter?
Dette vegkart-søket etter trafikkmengde på E39 i Stad kommune:
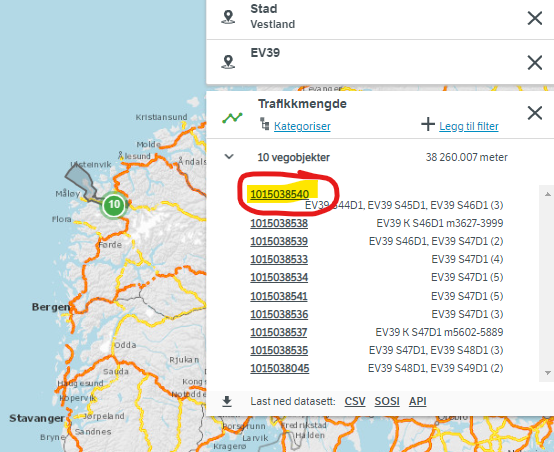
gir 10 vegobjekter. Men tar du ut en CSV-eksport fra dette søket får du 34 rader:
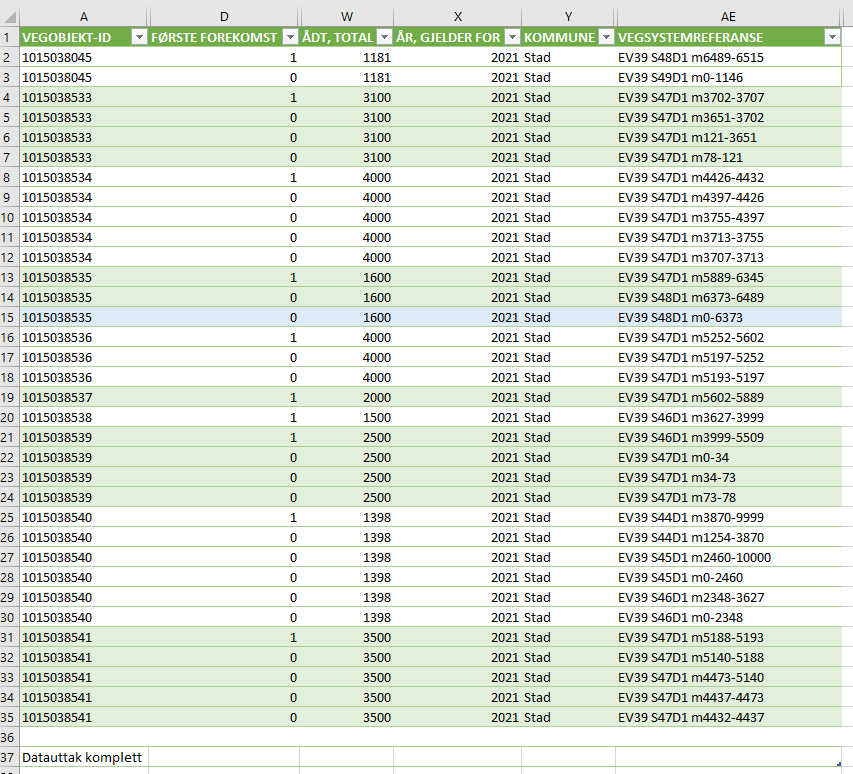
Hvordan kan dette ha seg? Hvordan blir 10 objekter til 34 rader?
Hvis vi ser nærmere på objekt ID 1015038540 i vegkart så ser vi at her har vi tre vegreferanse-oppføringer, en for strekningsnumrene 44, 45 og 46
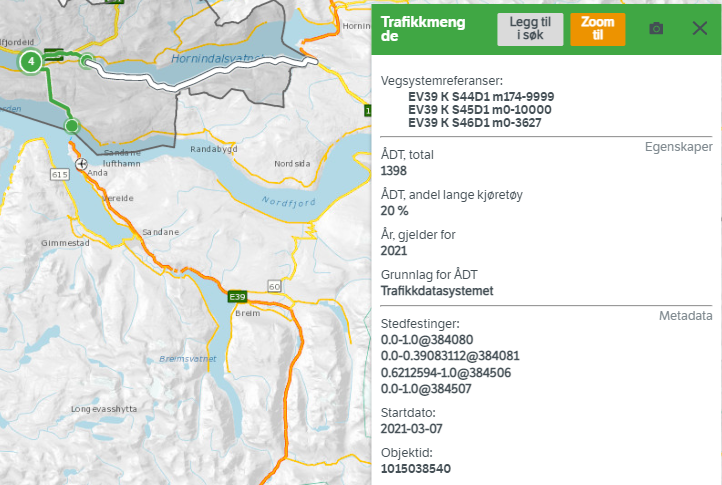
I CSV-eksporten er dette blitt til 6 rader:
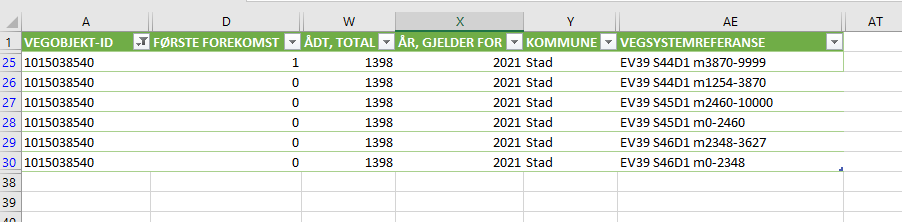
Dette er dobbelt så mange rader som i vegkart-visningen. Grunnen er at vi tar hensyn til flere andre faktorer når vi avgjør hvor mange rader som trengs i tabellen. Det blir selvsagt ny rad når vi bytter strekning- eller delstrekningsnummer (slik som vegkart). Men vi bryter også opp i ny rad der vi krysser grensene til et kontraktsområde eller en kommune, eller der vi bytter til en ny lenkesekvens på vegnettet.
En «flat tabell» har begrensninger
Når vi lager eksport til denne typen «flate tabeller» er det to ønsker som ikke lar seg forene:
- Vi ønsker en rad per NVDB objekt
- Vi ønsker en intuitiv presentasjon av vegsystemreferanse (per vegnummer, strekningsnummer, delstrekningsnummer og evt sideanlegg eller kryssdel).
Vi la mest vekt på det siste ønsket, der vi bryter opp hvert objekt i så mange biter som nødvendig. Dermed blir det enklere å håndtere detaljene om vegsystemreferanse (samt også informasjon om kontraktsområder, kommuner, lenkesekvens og geometri etc)
For å imøtekomme det ønsket om en ryddig presentasjon med én rad per NVDB objekt har vi innført kolonnen «Første forekomst». Filtrerer du vekk de radene der det står tallet 0 i kolonnen «Første forekomst» så får du en rad per NVDB objekt.
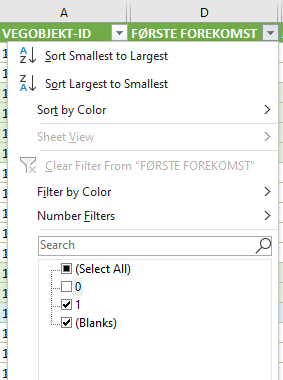
Merk at da får du ikke den fullstendige vegreferansen, kun den delen som tilfeldigvis havnet på raden med Første forekomst = 1. For å se den fullstendige utstrekningen langs vegnettet må du også vise radene med første forekomst = 0.
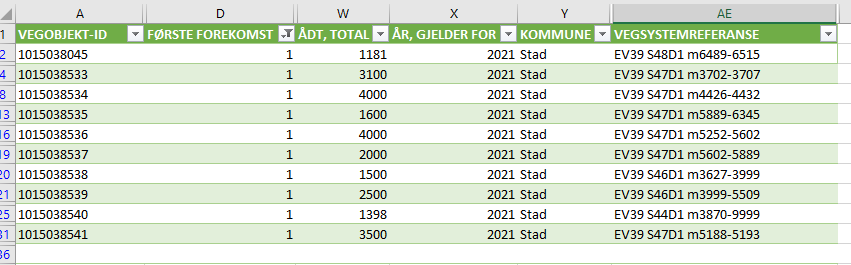
PRO-TIPS: Åpne CSV fil med Data->importer
Ett siste tips: Ikke dobbeltklikk på den ferdige CSV-filen, eller la Excel åpne den automatisk. I stedet bør du importere til et blankt regneark. Åpne et blankt regneark, velg fanen «Data» og klikke «Fra tekst/CSV»
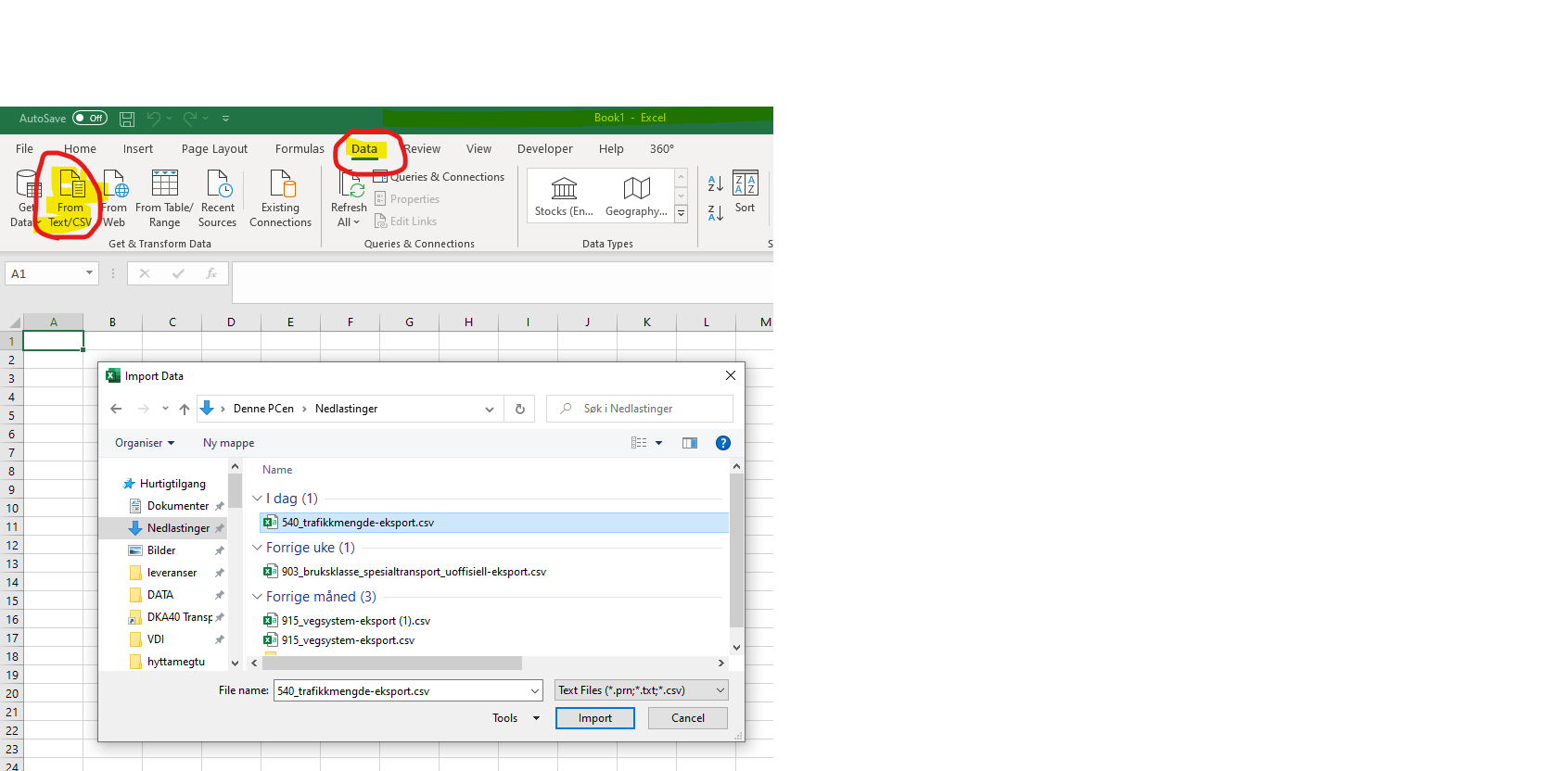
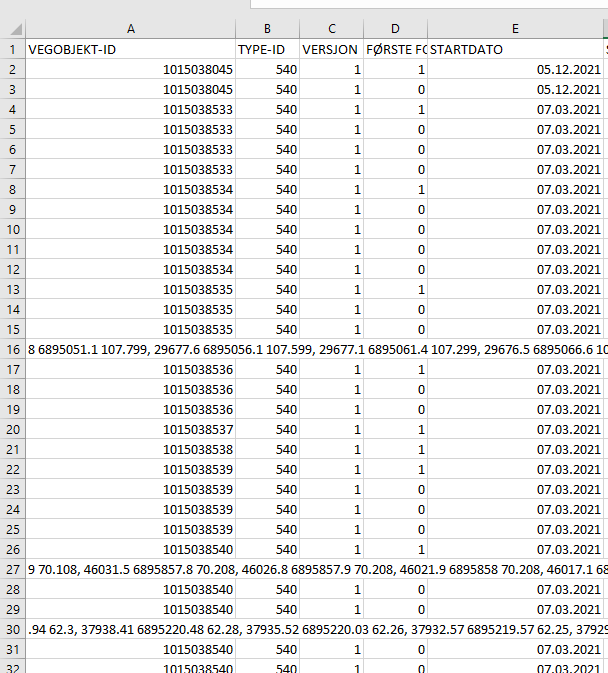
Denne importfunksjonen er langt mer robust enn Excel sin standardrutine for å åpne CSV, som noen ganger blir forvirret av eksporten vår. I eksemplet under så fikk vi feil på rad 16, 27 og 30. Disse tilhører egentlig «geometri»-kolonnen til raden over, men Excel har ikke klart å tolke det rett.
I tillegg til mer robust datainnlesning så får du også automatisk tilrettelegging for en del fine filterfunksjoner og tabellen blir mer lettlest.