Her er oppskrift på hvordan du kan ta ut historiske data for trafikkmengder i ulike verktøy. I prinsippet er enkelt – du føyer til parameteren tidspunkt=VALGT DATO i spørringen til NVDB api LES – i tillegg til andre søkeparametre (som f.eks kartutsnitt m.m). Alle spørreparametrene er beskrevet i dokumentasjonen for NVDB api LES.
For å få all tidsutvikling i samme spørring kan du i stedet for tidspunkt bruke parameteren
alle_versjoner=true(for vegobjekter). Resultatet blir litt mer uhåndterlig spagetti med absolutt alle historiske og nåværende data fra NVDB, og krever gjerne litt sortering, filtrering og gruppering før man får struktur på dataene. For vegnett heter denne parameterenhistorisk=true.Sjekk også vår artikkel om Snublefeller, historiske data
Nedenfor viser vi eksempel på gamle og nye data for biter av gammel og ny E18-trasé ved Arendal. Den nye motorveien Arendal-Tvedestrand åpnet juli 2019, og trafikkmengden på gammel E18-trasé (nåværende Fv421) har gått ned med om lag 10.000 kjøretøy per døgn.
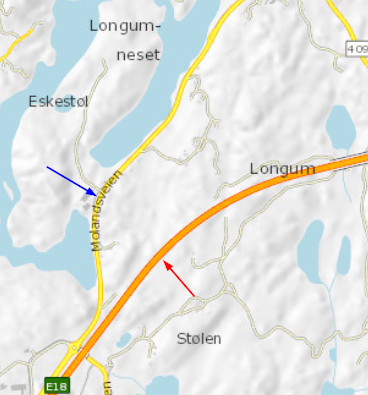
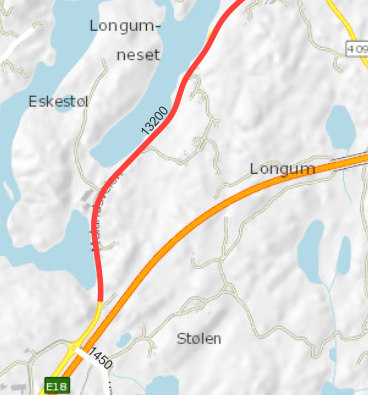
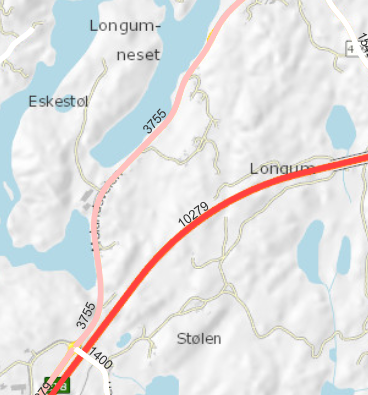
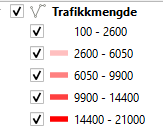
EDIT: Vegkart støtter nå historiske data
Våren 2022 satte vi i produksjon vegkart med støtte for historiske søk. De historiske søkene er fremdeles tregere enn standardsøkene, men det er etter vårt syn til å leve med.
Vi har laget ferdig en vegkart-versjon der du kan søke etter historiske data, men det gikk for tregt til at vi kunne produksjonssette den. Vi opplevde kanskje 20-30 sekunders ventetid før vegkartspørringen etter historiske data ga respons – og dette er helt uaktuelt å tilby brukere av en moderne webløsning i 2021. Historiske søk kommer nok til vegkart, men vi trenger mer tid før det blir bra nok.
Vegkart eksport – SOSI og CSV
Her er et tjuvtricks som bruker CSV- og SOSI eksport for å laste ned historiske data – det fungerer, selv om vegkart ikke innbyr til det. Gjør et vegkart-søk og kopier nedlastingslenken fra søket ditt (ekspander treffboksen og høyreklikk over det klikkbare feltet CSV eller Sosi for å få tilbud om å kopiere lenken). Denne lenken limer du inn i en teksteditor og føyer til valgt dato på formen &tidspunkt=2021-03-15 Merk at spørreparametrene skal være adskilt med ampersand (& – tegnet).
Denne modifiserte lenken kan du så lime inn i nettleserens adressefelt + ENTER. Nedlastingen skal nå starte automatisk.
&tidspunkt=2021-03-15 FME
Eksempel workspace for nedlasting av historiske trafikkmengde finner du her https://github.com/LtGlahn/nvdbapi-v3-FME
Argcis Pro
Firmaet Geodata A/S tilbyr en geoprosesseringstjenste hvor man asynkront kan laste ned data fra NVDB. Data blir pakket om til en esri-vennlig datastruktur på fil-geodatabase format, og når det er ferdig får du epost med lenke til nedlasting. Menyvalg for område, objekttyper, egenskapsverdier og andre typer filter blir bygget dynamisk i arcgis pro når du kobler deg til. De fleste (og viktigste) filtreringsmulighetene er støttet, men ikke alle. For eksempel tilbys menyvalget tidspunkt=DATO, men ikke historisk=true.
Qgis 3
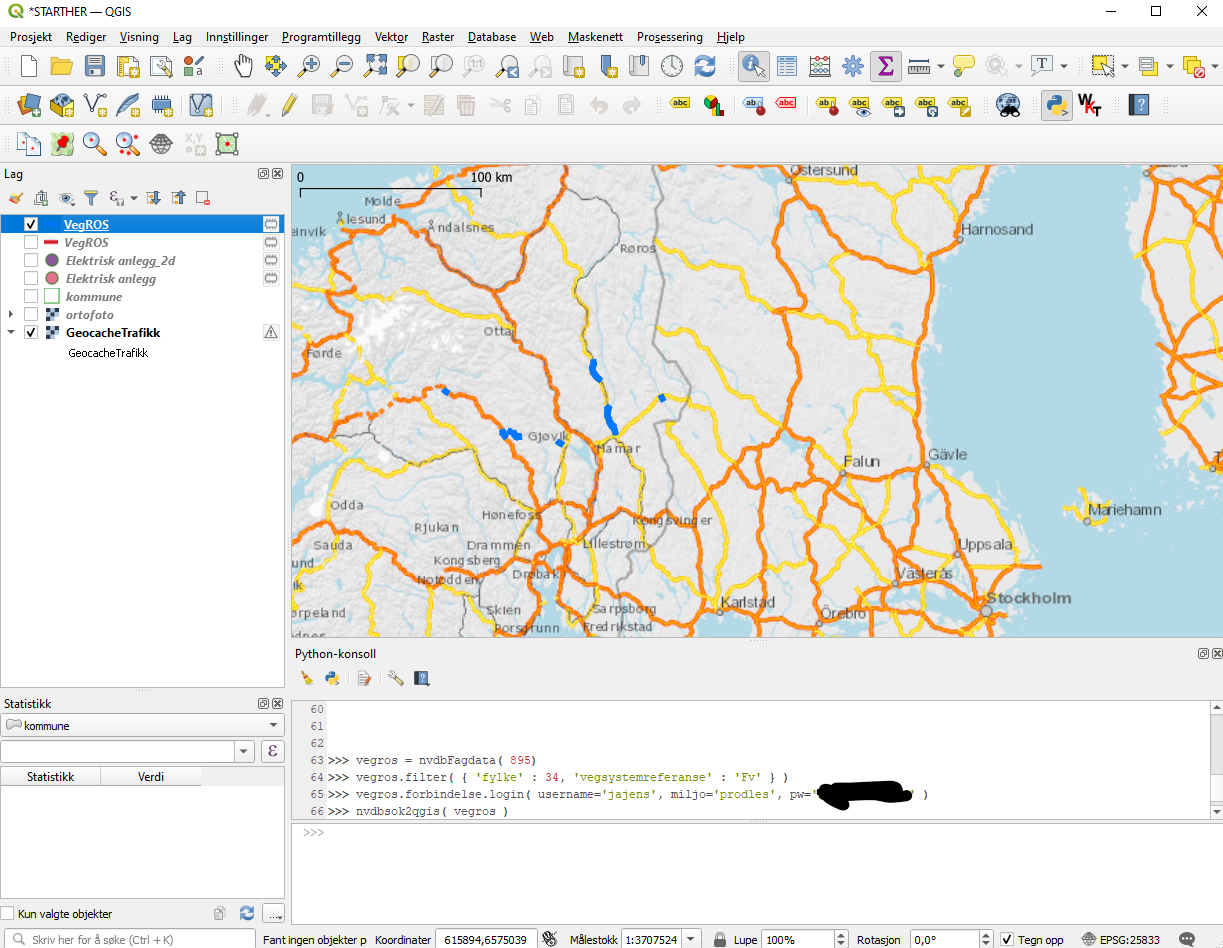
Vi har laget et python-bibliotek hvor du bruker python konsoll for å laste ned data fra NVDB api LES direkte til kartflaten i QGIS 3, det finner du her. Følg oppskriften for nedlasting og kjør scriptet qgis3script-importernvdbdata.py med dine lokale tilpasninger, slik at biblioteket blir riktig importert til python konsollet. Deretter er du klar til å laste inn data med kommandoene
traf = nvdbFagdata( 540 )
traf.filter( { 'kommune' : 4203, 'tidspunkt' : '2019-04-01' } )
nvdbsok2qgis( traf )
NVDB rapporter
Naviger til og velg egendefinerte rapporter. Menyen for å velge objekttyper er todelt: I den venstre menyen søker du etter Trafikkmengde og huker av. Bruk pilene for å flytte markerte objekttyper over til høyre meny – som er de objekttypene som kommer med i rapporten.
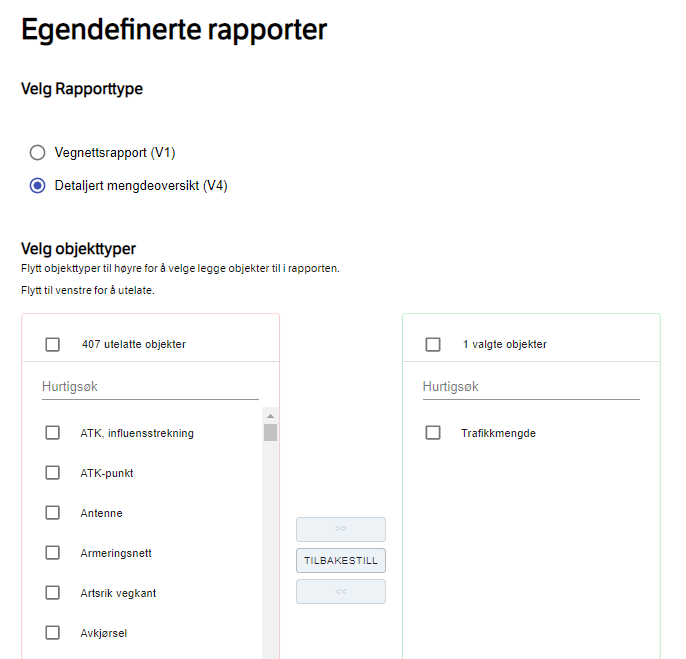
Scroll lenger ned for å velge område. For dataene i vårt eksempel har vi brukt valgene kommune = Arendal og tidspunkt = 2019-04-01
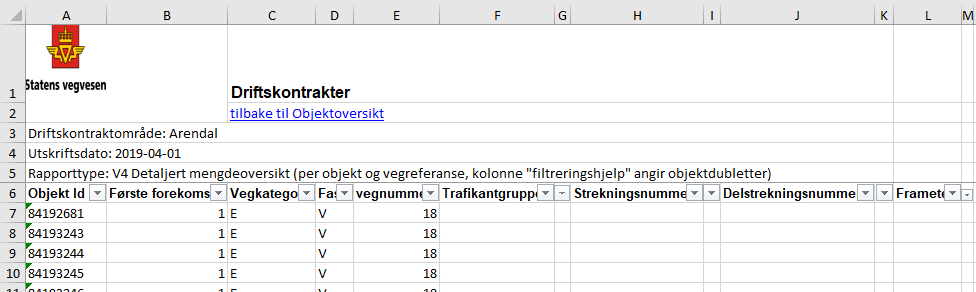
Den ferdige rapporten får litt begrenset bruksverdi når vi henter data som er eldre enn vegreferansesystemet som ble innført november 2019. I den ferdige tabellen er det derfor kun fyllt ut data for vegnummer, ikke strekning, delstrekning og meter – og dermed er det litt tungvint å vite hvilke rader som er hvor på vegnettet.
Python
Den mest elegante metoden er å bruke det fulle GIS-arsenalet blant annet geopandas, men ikke alle trenger dette – og installasjonen kan være litt fiklete. Derfor har vi skilt lesing fra NVDB (som funker rett ut av boksen i plain python) fra de avanserte GIS-bibliotekene (som kan være litt plundrete å installere rett). Starter du fra scratch med python så anbefaler vi Anaconda-distrubusjonen, og så fortsette med bruke conda-systemet for pakkehåndtering og bruke conda til å lage et separat python-miljø (detaljert oppskrift).
Selve nedlastingen gjør du med dette python-biblioteket som du laster ned https://github.com/LtGlahn/nvdbapi-V3, og last ned data med kommandoene
sys.path.append( 'Sti til der du har repos https://github.com/LtGlahn/nvdbapi-V3' )
import nvdbapiv3 # reposet https://github.com/LtGlahn/nvdbapi-V3
traf = nvdbapiv3.nvdbFagdata( 540 )
traf.filter( { 'kommune' : 4203, 'tidspunkt' : '2019-04-01' } )
myList = traf.to_records() Nå har du data i minnet som en liste med json-dictionaries, og det kan jo knas videre i alle retninger.
En mulighet hvis du har pandas, geopandas og shapely-biblioteket installert kan du for eksempel lagre det som kartlag til harddisken din. Her går vi omveien om en såkalt dataframe til en geodataframe, som igjen har funksjoner for å lagre til et knippe geografiske formater – for eksempel det suverene filformatet geopackage
import pandas as pd
import geopandas as gpd
from shapely import wkt
mydf = pd.DataFrame( myList )
mydf['geometry'] = mydf['geometri'].apply( lambda x : wkt.loads(x) )
mydf.drop( 'geometri', 1, inplace=True )
myGdf = gpd.GeoDataFrame( mydf, geometry='geometry', crs=5973 )
myGdf.to_file( 'trafikkmengde.gpkg', layer='trafikkmengde2019-04-01', driver='GPKG' )
Datadump, eldre data
I 2020 og 2016 laget vi datadump med alle (datitdens) gyldige og historiske trafikkmengde-data. Ved siden av la vi også en dump av objekttypen 532 Vegreferanse, slik at man hadde mulighet til å se hvilke vegnummer som var gyldige til ulike tider på en bestemt strekning.
Info om datadumpen finner du her (vegdata-artikkel fra 2016, oppdatert med 2019-data. Når jeg sier 2019-data er det dette de ÅDT-verdiene som var tilgjengelig i 2019, dvs med År, gjelder for = 2018.
Sinus infra
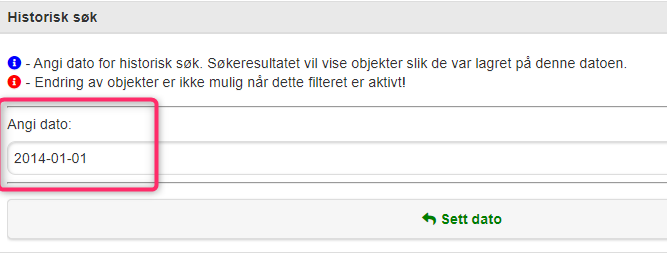
I Sinus Infra kan du ta ut historiske data som var gyldige på en bestemt dato. Søk fram Trafikkmengde og trykk på områdefilter:
Velg Historisk og sett ønsket dato. Angi geografisk område (kommuner, fylker, kartutsnitt, eller som vist her – søkeradius i meter).
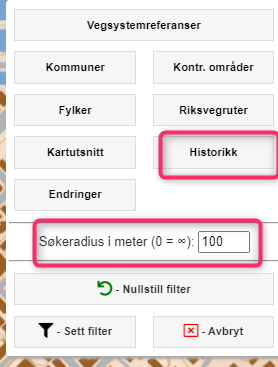
Angi søkedato som skal brukes: