Meld deg på Veg- og transportdatakonferanse i Trondheim
Veg- og transportrelaterte data har aldri vært mer aktuelle i samfunnsnyttige tjenester. For at bruken av disse dataene skal gi verdi, må de være sammenlignbare og ha kjent kvalitet. Alle leddene i verdikjeden fra innsamling og etablering av datasett til uttak og bruk, henger nøye sammen.
Konferansen for Veg- og transportdata ønsker å ta for seg deler av denne verdikjeden for å se behovene fra flere sider.
Problema i Les var løyst rundt 16:15 i går 2/6. Kort tid etter var NVDB oppdatert og tilbake i normal drift. Alle system skal no ha normal tilgang til NVDB-data igjen.
Original melding 2/6 2022 – 15:15:
Det har oppstått problem med handsaming av eit endringssett som kom inn til NVDB rundt 13:15 i dag. Det har skapt ein del ustabilitet i Les og Les har no slutta å svare på dataforespørjingar.
Dette fører til at alle system som nyttar NVDB-data no er ustabile.
Klokka 12:07 16. mars fekk NVDB-IND problem med ei endring i vegnettet. Dette førte til auka serverbruk som førte til fullstendig frys i Les rundt 13:00.
Les fekk vi raskt tilbake med enkle justeringar i servelast, men IND stod fast på vegnettsendringa heilt fram til rundt 15:30 der vi klarte å «hoppe over» den aktuelle endringa og gå vidare med køa.
NVDB funger no som normalt igjen, med eit lite unntak. på fv. 410, fv. 420 og tilstøytande vegar i Arendal er det avvik mellom vegnettet som er registrert i Skriv (og databasen) og det som er vist ut til verda gjennom Les. Dette vil føre til problem dersom nokon forsøker å gjere endringar i dette området. Det ligg difor ein lås på det berørte området og endringar som er innanfor låsen vert ståande på vent til vi har løyst det lokale problemet.
Når låsen er fjerna vert dei lagt inn i køa som nye endringar og vi reknar med dei fleste går gjennom, men enkelte kan verte avviste på grunn av at objektet er oppdatert av andre enringssett i området.
NVDB Les-API er tilbake i normal drift og oppdateringa ser så langt ut til å vere ein suksess. Vi har fått inn normalt med endringssett så langt i dag, og har ikkje registrert kø enda.
Oppdatering 11. mars:
Test i våre testmiljø er veldig positive. Vi har utført testing med registrering av fleire endringar i NVDB enn vi normalt har i produksjonsmiljø samstundes som vi simulerte ekstrem last på API-et med mange store spørjingar i Les.
Resultatet var at vi berre opplevde midlertidig kø på få minutt i samband med endringar i vegnettet. Men køa tok seg inn igjen etter få minutt. Vi opplevde og at Les er litt tregare (brukar litt lengre tid på å svare) når lasta er størst. Dette var og forventa, men vi reknar gevinsten med å få tilgang på oppdaterte data raskare som større enn ulempene med at svartida vert litt større.
Planlagt oppdatering
Vi driv testing av ei endring i NVDB som skal redusere tida som går med til indeksering av data – eller tida det tek frå NVDB mottek ei endring til den er tilgjengeleg i Les.
Vi har gode erfaringar med testing så langt og ser ut til å kunne redusere tidsbruken med opp mot 90%. Det vil sei at vi kan gå frå dagens situasjon der vi midt på dagen får inn meir enn dobbelt så mange endringar kvart minutt enn vi kan handsame, og dermed kontinuerleg bygger opp kø, til å kunne handsame opp til dobbelt så mange endringar som vi får inn no.
Konsekvens under oppdatering
Men innføring av endringa vil føre til komplett nedetid for Les-API og dermed alle system som er avhengige av dette (Vegkart, Datafangst og eksterne klientar som viser eller nyttar data i NVDB).
Reserveløysing
API v2 og Vegkart-2019 vil vere tilgjengeleg, men det er her ikkje informasjon om vegsystem eller nye fylkes- og kommunestrukturar. Det kan brukast for å finne fagdata om vegobjekt, men vil då innehalde gamle referanse til vegnett, fylker og kommunar.
Vi ser gevinsen med å innføre denne endringa som så stor at dersom vi ikkje finn store problem under testing fra til fredag vil vi innføre det alt no i helga (startar arbeidet fredag 11. mars 2022 kl 16:00). Dette er kort varsel, men vi har arbeida lenge med å finne ei løysing på dette problemet som stadig vert sørre og som vi får veldig mange tilbakemeldingar på at skaper problem for våre brukarar. Dersom dette fører til store operasjonelle problem for nokon ber vi om tilbakemelding på dette til NVDB@vegvesen.no.
Vi er nødt til å ta ned API-Les i ATM/test-miljø for å teste ei endring vi planlegg i PROD til helga. ATM Les vil då vere nede frå eit tidspunkt no i ettermiddag (3/3 2022) til i morgon formiddag ein gong.
Målet med endringa er å kraftig redusere tidsbruken i IND som vil gjere at ventetida frå registrering i Skriv til data er tilgjengelg i Les vert betydeleg kortare enn i dag. Potensiell gevinst her er så stor og etterspurd at vi prioriterer å teste dette i ATM no så vi kan innføre det i PROD alt denne helga.
Les først dokumentasjon du finner under menypunktene eller ved å søke her på vegdata.no og vegvesen.no.
Finner du ikke svar, ta kontakt med NVDB igjennom kontaktskjemaet.
Melde feil i NVDB?
Informasjon i Nasjonal vegdatabank (NVDB) er registrert på en systematisk måte, og holder jevnt over høy kvalitet. Men trenger du like vel å melde feil i NVDB? Her finner du en oversikt over hvordan du melder fra.
Database oppgraderes, og det meste i testmiljøet vil være nede fra 8:30.
Samtidig vil vi klone produksjonsbasen over i ATM for å få ferskere data i testmiljø. Nye data må da indekseres og vi venter at testmiljøet er oppe i normal drift først tirsdag 19. oktober.
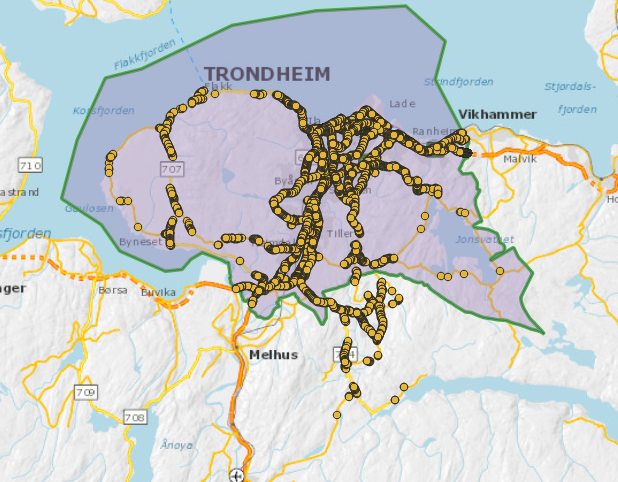
Det vi trenger er en oversikt for hva som er nytt per år. Altså hvis en veg får flere gatelys, fortau osv.
Dette er et behov som mange vegeiere og -driftspersonale har. Akkurat denne gangen kom spørsmålet fra Trondheim kommune, men det samme behovet har fylkeskommunene, entreprenører, Nye Veier A/S og Statens Vegvesen.
Vår anbefaling: Ta differansen mellom to datasett for ulike tidspunkt
NVDB api LES støtter datauttak på angitt tidspunkt (dato), med et par forbehold om at det ikke har vært gjort endringer på områdegrenser fra det første tidspunktet til i dag. Her er status på historisk søk i ulike verktøy per oktober-2019:
NVDB rapporter, alle rapporttyper støtter datauttak på angitt tidspunkt. I denne sammenheng er det driftskontrakt-rapportene som er mest relevant.
Vi har testet historiske søk i Vegkart. Det fungerte, men ytelsen var ikke bra nok. Vi jobber med saken!
Vi har noen forbehold! Hvis det har vært gjort justeringer på kontraktsområder og/eller vegnett kan du få litt … lite intuitive resultater, se under. I tillegg får du litt merarbeid om du ønsker å sammenligne data før og etter en kommunesammenslåing.
NVDB bruker kun de nyeste kommunegrensene!
I NVDB bruker vi kun ferske data for fylker og kommuner – med tilbakevirkende kraft. Så i 2021 finner du for eksempel ingen spor etter gamle Klæbu kommune.
Dette betyr at når du søker etter belysningspunkt i Trondheim for en tidligere dato, for eksempel 1. februar 2017, så får du treff pådagensTrondheim kommune. Mer presist 10625 objekter, hvorav 927 er i gamle Klæbu kommune.
Selv om Trondheim og Klæbu først slo seg sammen i 2020 så gir søket etter belysningspunkt per 2017 deg 927 treff i gamle Klæbu kommune,
Men hva med endret – funksjonen i NVDB api? Hvorfor ikke bruke den?
NVDB api LES tilbyr parameteren endret_etter, og den har sin anvendelse – men for akkurat dette behovet blir det for mange snublefeller. Resultatene fra denne spørringen:
må suppleres med en hel del datamassasje: Du må skille endret fra nye objekter, evt om det er nye versjoner av gamle objekt – og du må sjekke om noen objekter kan være slettet. Etter vårt syn er det bedre å ta differansen mellom to ulike datoer.
Historiske data per Kontraktsområde – brukes på egen risiko
Hvis du henter ut historiske data for et kontraktsområde og enten vegnettet eller kontraktsområdet (eller begge deler!) har vært endret så må vi ta forbehold om at du kan få færre vegobjekter enn det riktige.
Hvis du vet at vegnettet og ditt kontraktsområde har ligget i ro i tiden mellom i dag og bakover til det eldste tidspunkt du trenger data for – så kan du helt fint ta ut historiske data på dette kontraktsområdet.
Forklaringen er komplisert: Når kontraktsomrdet skal brukes som søkefilter i NVDB api les så klarer vi ikke gjenskape området slik det så ut før endringen, men bruker området slik det ser ut i dag – også for historiske søk.
Hvis en bit av vegnettet var i k.området i 2019, men ble satt historisk i 2020 – så vil du ikke klare finne den når du søker på k.området i dag med tidspunkt=2019.
Tilsvarende hvis k.området har vært justert i 2020: Du klarer ikke få frem riktige 2019-data ved å bruke k.området som søkefilter.
Det finnes krokveier om dette problemet, men det er komplekst (hent ut historisk 538-objekt per tidspunkt, finn dette objektet stedfesting og hent ut vegobjekter som hadde overlappende stedfesting på det tidspunktet.) Vi ønsker å tilby ferdige rapporter basert på denne logikken, men det ligger noe fram i tid.
NVDB API Skriv har blitt etablert i nye driftsmiljøer på Atlas-plattformen hos Statens vegvesen. Vi har hatt begge miljøene opperative i en god periode nå og regner med mange har byttet til nye URLer. Vi vil nå starte prosessen med å stenge av de gamle URLene, og ber nå alle brukere om å se over at alle system er oppdatere med nye URLer.
Planlagt stenging av gamle URLer er 1. juli 2021.
På grunn av tilbakemeldinger om at ikke alle systemer har oppdatert URL-ene til de nye utsettes stenging av gamle adresser til August 2021. Vi kommer tilbake med ny dato etter hver som vi får tidsplan fra de systemene som ikke er klare.
Siden dette kom nært opp til ferie for mange og at informasjonen ikke ser ut til å ha nådd frem til alle i tidligere faser er vi litt fleksible med nedstengingsdato her.
I Atlas-miljøet brukes en ny autentiseringsmekanisme, basert på OAuth2 (OpenId Connect). Når klienter skifter over til nye URLer må derfor også autentiseringlogikken omprogrammeres. Hvordan dette kan gjøres er forklart på https://apiskriv.vegdata.no/autentisering.
Dersom det er spørsmål rundt dette, ta kontakt med nvdb@vegvesen.no.
Dersom det er behov for å holde det gamle miljøet oppe en stund til fremover må vi ha tilbakemelding om dette snarest med begrunnelse og dato for når det ikke er nødvendig lenger.