Vi legger om til å publisere nyheter på http://nvdb.no . Her har vi fremdeles et par innkjøringsproblemer, og i en overgangsperiode så blir det en viss grad av dobbeltpublisering på vegdata.no og http://nvdb.no
Forfatterarkiv: jankristian
Demo NVDB rapporter og datafangst 2022-06-14
NVDB rapporter
- Ny rapporttype produksjonssatt: Vegoppmerkingsrapport
- Nytt testregime tatt i bruk. Ved produksjonssetting verifiserer vi nå at de mest brukte rapporttypene ikke endrer datainnhold pga kodeendringer.
- Ny kolonne med sluttdato for objekter i alle rapporter med detaljert objektinformasjon
- Endret rapportnavn (uten mellomrom), som gir mer robuste lenker ved nedlasting.
- Noen forbedringer på å håndtere relasjoner.
Forslag: Kjøre batch-operasjon med flere kontraktsområde-objekt.
Gamle DF
Ikke så mye å melde.
Nye DF:
Felles innsats for å finne flest mulig feil. Fant et par designting som bør forbedres. Forbereder arbeid med kontraktsadministrasjon. Forbereder flere brukertester.
- Kan fjerne vegobjekt fra kontraktsadministrasjon
- Bedre tekst på «importer kommaseparert liste med NVDB ID»
- Leser ny variant av SOSI kvalitetsinformasjon geometri
- Zoom til vegobjekt viser nå alle objekter, selv om det er stor spredning.
- Forbedret visning av menyvalg, leveranseplan og fil.
Innsending til NVDB
Data sendes nå helt inn til NVDB api SKRIV
Systemet sender inn hele slektstreet (hvis nødvendig) når du sender inn et objekt som har relasjon til andre objekt.
DF 2.0 i testprod (ATM) miljø
Velge alle objekter i tabell samtidig
Info-boks ved innsending NVDB: Viser antall objekt som sendes til NVDB
Opprydding designstruktur registrering av kontraktsadministrasjon
Går mot stille lansering. Vil vise infoboks med kjente snublefeller
Demo NVDB rapporter og Datafangst 24. mai 2023
Rapporter:
Fikset bug med enumverdi av typen flyttall
Relasjonsrapport: Rammet av samme svakhet som LES: Relasjoner fra mor til datter blir først oppdatert ved full re-indeksering (hver fredag). Dvs hvis du redigerer relasjoner vil ikke relasjonsrapporten vise dem før i neste uke.
Jobber med automatiserte tester av datainnhold (sikre at datainnhold ikke endrer seg ved kodeendring)
Eksisterende DF:
Støtte FKB Sosi 4.6 samtidig med FKB 5.0
SPM: Ikke foreslå sideposisjon «midt» dersom vegobjektet krysser senterlinja. Dette er feil for nesten alle objekttyper.Svar: Tusen takk for innspill, det er notert og vi videreformidler til teamet som har ansvar for stedfestingmodulen.
Nye DF – Design og utforming:
Lukking av objekt som har relasjon: Tilby å erstatte moren
Stor UI oppdatering med fokus på tilgjengelighet (kontrast, størrelse m.m.)
Sammenlignet «kontraktløs» opp mot redigering på kontrakt, fant 9 forbedringspunkter som gir bedre samsvar mellom disse delene av nye DF
Nye DF – status utviklng
Sendt til NVDB – knapp, bekreftelsesknapp. Flyttet funksjon til «stedfesting og sammenkobling»
Importere liste med NVDB ID til datafangst
SPM: Format på liste: Svar: Kommaseparert, vi finpusser litt på GUI så dette blir litt tydeligere.
SPM: Lime inn Vegkart API-URL, slik som i gamle løsning? Svar: Vi vurderer det. Dette behovet overlapper også delvis med at du i nye DF kan hente data fra NVDB i kartutsnitt. Men vegkart-filtrene er pt mye mer presise enn DF sine filtre, så p.t. er ikke DF sin løsning like bra som lenken fra vegkart.
Vise bekreftelsesknapp: Sender du inn ett objekt så sender du også inn de øvrige objektene i dette relasjonstreet. F.eks send inn ett skiltpunkt og du får med evt skiltplate-døttre (og evt også de døttrene eller mødrene som skal kobles fra). Har laget ny logikk for å regne ut hvilke objekt som skal være med i endringssettet basert på nye og endrede / slettede relasjoner.
Jeg kan visuelt endre verdier i tabell. Gul-markering av endrede egenskapsverdier. Lukke-knapp
SPM lukkeknapp, hva lukker man? Svar: Man lukker i NVDB. Endre utseende slik at det står «lukk i NVDB»
SPM Må kunne velge lukketdato. SVAR: Enig, notert.
SPM: Samkjøring med FME kvalitetskontroller som kjøres fra f.eks. FME server? Svar: Vi tilbyr åpent API slik at det f.eks blir mulig å opprette kontrakt og legge inn data på den kontrakten fra FME – når det er hensiktsmessig. Det blir også mulig å f.eks. gjøre høydekontroll av data mottatt på kontrakt ved at FME leser ut de dataene som er mottatt på den kontrakten.
Demo
Redigering av egenskapsverdier.
SPM: Hva betyr krysset for hver kolonne? SVAR: Du skjuler den kolonnen.
SPM: Kan vi endre bredden på kolonner? SVAR: Ikke ennå, men det kommer senere. Vi prioriterer at redigeringsfunksjonene virker foran slike generelle «jobb-bedre-med-tabell» oppgaver.
SPM: Hente NVDB objekter på gyldighetsdato. SVAR: Ikke ennå.
Har 9 Gjenstående oppgaver før produksjonssetting – stille lansering av mangelfull løsning.
SPM: Må leverandørene gjøre mye arbeid for å tilpasse seg nytt DF api? SVAR: Ikke egentlig, men i praksis må de skrive koden på ny (ny løsning for autentisering, data må sendes på en litt annen måte enn før). Men logikken på de operasjonene man gjør i gamle DF vil man finne igjen i nye DF. Dette er enkle operasjoner, så omskrivingen bør være en liten og høyst overkommelig jobb.
SPM: Må Sinus infra / sinus entreprenør komme i to ulike versjoner, en for ny og en for gammel DF? SVAR: Det må du nesten spørre Triona om. Det kan godt hende de velger å tilby datainnsending til både ny og gammel DF i sin løsning.
Demo NVDB rapporter og Datafangst 12.4.2023
Rapporter
Invisterer tid på å lage gode tester slik at vi fanger opp eventuelle sideeffekter av fremtidige endringer. Har ikke noe konkret å vise fram på denne demoen.
Datafangst
Varsle om at sosi 5.0 ikke skal brukes før mai 2023.
Feil som ga mangelfulle kvalitetsdata. Potensielt kunne dette gjelde flere hundre tusen objekter, i praksis viste det seg å gjelde 14 – fjorten – vegobjekter. Disse er rettet i NVDB.
Nye DF
Status designere (UX)
Har primært jobbet med design av innsending til NVDB: Tabell som viser hvilke objekter som er sendt inn til NVDB, eventuelle feilmeldinger fra SKRIV osv.
Status utviklingsarbeid nye DF
Vise relasjonstre: Bedre synkronisering slik at visning av relasjonstre alltid gjenspeiler endringer gjort andre steder i applikasjonen. Spesielt viktig at frakobling eller tilkobling er synkronisert i alle visninger av relasjonstre. Fikk forslag om å koble objekter to ganger, dette er rydda vekk. Endret fargevisning slik at det ikke blir forvirring mhp farger i tabell og farger i kart. Ventestatus (spinner-animasjon) og deaktivering av knapper når systemet jobber. Bedre tilbakemelding ved sammenkobling.
Stedfesting: Jobber med å gå fra designskissenene til implementasjon. Redigeringsmodus for stedfesting. Vise stedfesting (under arbeid). Klikk på vegsystemreferanse skal gjøre at vegen blir markert i kartet (under arbeid). Stedfestingoperasjon.
Annet: Hvem spiste veglenkene (sikre at alle veglenkene blir vist), minnelekasje, rettet zoom-feil i kartet, estimering av gjenstående arbeid før produksjonssetting.
SPM: Fint om vi får en «koble fra alle»-knapp på morobjektet. SVAR: Ja, jobber med denne funksjonen – det skal bli mulig.
SPM: Datafangst kontrakten, ønsker oversikt med fra-til på vegsystemreferanse (utstrekning langs veg). Notert.
Demo nye Datafangst
Viser vegnett i kart. Klikke i kartet og få opp objekthierarki med skiltpunkt og skiltplate. Viser at vi kobler fra en skiltplate fra skiltpunkt. Vente-symbol og nå blir relasjonstre oppdatert i begge modalene. Klikker på en veglenke og får fyllt ut stedfest-boksen med denne vegen som forslag.
SPM: Kan vi skille visuelt hva som er hentet fra NVDB og hva som er lastet opp på kontrakt. SVAR: Ja, det kommer.
Plan videre:
Har estimert gjenstående oppgaver for stedfesting+sammenkobling og de aller mest nødvendige funksjonene for kontraktsadministrasjon og lagring til NVDB.
Etter produksjonssetting av «stedfesting og sammenkobling»
SPM: Håndtering av versjonskonflikter. SVAR: Har ideer til løsning for bedre håndtering av versjonskonflikt.
SPM: Flyfoto / ortofoto. Ønsker ferskest mulig bildegrunnlag. SVAR: Ja, gi oss detaljer om tilganger til bildetjenester (bakgrunnskart) så løser vi det.
SPM: Terratech sin «mapspace». SVAR: Samme svar, gi oss detaljene om tilganger etc, så er det løsbart.
Demo NVDB rapporter og Datafangst 22.3.2023
Rapporter:
Mye sykdom denne sprinten. Jobber med større oppgradering av automatiske tester.
Gamle Datafangst.
Har fikset bug som kan ha gitt mangelfulle kvalitetsdata. Bug’en var virksom fra juni 2022 til februar 2023. Jobber med å avdekke omfang av feil som kan ha blitt introdusert av bug’en og finne gode tiltak for feiloppretting. EDIT 30.3.2023: Nærmere undersøkelser avdekket at vi totalt snakker om 14 endringssett som har gitt mangelfulle kvalitetsdata i NVDB. VI har en oppskrift på å rette dette opp, og vil ordne opp i dette.
SPM: Blir fort «doppelt opp» med data i DF ved filopplasting. Sliter med å gjenskape problemet, men har en teori om at det er knyttet til at DF er aktiv i flere faner (vinduer) samtidig.
Status UX design nye Datafangst:
Hovedfokus akkurat nå er av data til NVDB, hvordan tabell for innsending skal se ut, god dialog for å velge hvilke objekter som skal sendes inn, med hvilke operasjoner, og status på de objektene som er sendt til NVDB. Dette er naturlige «siste steg» av stedfesting og sammenkobling.
Utvikling nye Datafangst:
Sammenkobling: Ikke etterspør relasjonstre med kun ett objekt. Blir tvunget til å gjøre valg før du kan trykke på «Søk»-knappen. Fjerner grønn prikk fra relasjonstre fordi fargen på prikken ikke stemmer overens med farger i kartet (synkronisert symbolisering kart og andre menyelement kommer senere). Ventestatus ved sammenkobling. Oppfrisking av relasjonstre ved sammenkobling (synlig resultat uten refresh)
Stedfesting: Kodet skjema for redigering av stedfesting. Foreløpig uten de nødvendige funksjonene (det kommer!). Jobber med å hente og vise vegnett i kart.
Annet: Kan søke på enkeltobjekt med ID i kart. Opprydding popup, bedre ytelse. Bedre import og opprettelse av vegobjekter (opprydding og bedre ytelse). Bedre tilbakemelding til brukere underveis i tunge operasjoner. Byttet avkrysningsboks med radioknapp, mer intuitivt for disse valgene.
Demo ny Datafangst
I databehandlingsfanen, skiltpunkt + skiltpunkt. Kan fjerne eksisterende kobling. Kan søke etter mor eller datter-relasjon fra NVDB eller blant data opplastet til DF. Får opp sammenkoblingskandidater med avstand. Foreløpig vises sammenkoblingskandidater med syntetisk ID, bedre visning kommer etter hvert. Viser hvordan skiltplate kobles sammen med nærmeste mor, valgt i liste
SPM: Fikk du vist mor i kartet når du valgte mor? Nei, vi har ikke foreløpig noen synkronisering mellom valgt mor-objekt for sammenkobling og kartvisning. Det kommer
SMP: Får vi endret geometri ved sammenkobling? Nei, men det ligger i planverket. Må jobbe fram hvordan dette skal fungere, og hvordan de ulike valgene presenteres for brukeren. (Skal vi hente geometri fra mor? Eller fra datter? Bruke den nyeste geometrien? Den med riktige kvalitetsparametre? etc)
Videre plan:
Ferdigstille fremdriftsplan
Stedfesting
Redigere i tabell
Innsending
SPM: Kommer det mere automatikk for sammenkobling, f.eks hvis du har flere hundre objekter? Svar: Manuell sammenkobling kommer først. Så legger vi på mere automatikk etter hvert. Dialogboksene er designet med tanke på at du skal kunne koble mange objekter samtidig.
SPM: Viktig at vi har god kontroll når vi skal jobbe med store objekter samtidig.
SVAR: Systemet skal kunne takle sammenkobling av f.eks en belysningsstrekning med mange belysningspunkt i én operasjon.
SPM: Ønsker å importere data basert på liste med ID. SVAR: Viser importer-dialog.
SPM: Få fram objekter med TO mødre. SVAR: Vær obs på falske positive i denne listen. LES sin presentasjon av «Foreldre» – relasjon viser fram mange relasjoner som ikke lenger er gyldige i dag. dette gjelder flertallet (men ikke alle!) av de «doble mødrene» som du finner i LES.
SPM: Fjerne relasjon på mange objekt samtidig (massefrakobling). God idé, notert.
SPM: Må vi bruke vegdata.no LENKE for å finne lenke til kalenderinvitasjon / Teams møte? Svar JA.
SPM: Teams-invitasjonslenke som ligger på vegdata.no LENKE er utdatert. SVAR: Takk, skal fikse.
Demo NVDB rapporter og Datafangst 1.3.2023
NVDB Rapporter:
Har jobbet mest med oppgradering på automatiske tester.
Gamle Datafangst
Justere zoom-krav for visning av eksisterende objekter. Mer tydelig i grensesnitt når man møter zoomgrensen og/eller for mange objekter til at vi kan laste inn alt.
Kryssende sideposisjon heter nå K (ikke X)
Bedre mottak av kvalitetsdata geometri (håndterte kun kortform, ikke blanding av langform (ny syntaks) og kortform (gammel syntaks). Dessverre må tidligere forkastede filer lastes opp på ny.
SPM: Kan vi få en rapport på hvilke data som er berørt, i Datafangst og i NVDB.
SVAR: Gjelder alle alle opplastede sosifiler etter en viss dato (ny innlesning) og denne fiksen her)
SPM: Etterlyser mere info. Bli flinkere å rapportere til alle slik at de
SVAR: Enig. Vi sjekker omfanget og går ut med info, enten til alle eller til de berørte (avhengig av omfang).
Nye datafangst – Sammenkobling av mor og potensielle døtre i nærheten
- Oppheve sammenkoblinger
- Oppheve sammenkobling opprettet i kontrakt
- Rask oppdatering av relasjonstre ved sammenkolbing
- Vise avstand til potensielle sammenkoblinger (for tyngdepunkt for linjer og flater, kan justeres til andre typer avstander)
- Tegne relasjonstre fra backend i popup (ikke ferdig ennå)
- Utvidbart relasjonstre i modal
- Vise nye objekter i sammenkoblingsmodal (ikke ferdig ennp)
- Vise nye relasjoner i modal etter kobling
Nye Kontraktløs innsending
- Bugfiks: Endringer av egenskapverdi forsvant når man byttet fane i nettleser
- Håndtere datatype «klokkeslett», «Kortdato»
- Datatype «struktur» blir ignorert (inntil videre, denne er lite brukt)
- Bugfix Kartet blinket
- Lukkking av popup lukker også redigeringskomponent
Nye Datafangst kart i kontrakt
- Åpne popup ved klikk på enkletobjekt i kontrakt
- Plassering av popup for linje og flategeometri (kommer der du klikker)
- Bugfiks Vegobjekter blinket
- Kartutsnitt manglet i dyplenking
Nye Datafangst – annet
Ordne ID-porten tilganger til DF2.0 for kjernebrukere.
Ta i bruk varslinger fra SVV designsystem
Mer funksjonell menylinje
Beskrivende navn på vegobjekter i kontrakt
Rydde opp i import og opprettelse av vegobjekter
Demo
Menylinje skjules automatisk
Demo sammenkobling klynge av objekter (skilpunkt, tre skiltplater og dokumentasjon). Fravelger dokumentasjon.
Merk at vi foreløping kun viser den interne ID’en for objektene, denne skal erstattes med mere beskrivende navn.
Klikk på enkeltobjekt (dokumentasjon-objekt), velg mor som denne skal kobles til.
Demo – kobler sammen ett skiltplunkt, tre skiltplater og ett dokumentasjonsobjekt (som hektes på ett av skiltplate-objektene). Viser frakobling og at relasjonstreet oppdateres.
SPM: Kan man se egenskapsverdier i denne modalen? Svar: Det kommer
SPM: Avstand – kan vi få den i millimeter eller cm? SVAR: Vi viser desimaler når avstanden er større enn 1mm.
SPM: Problemstilling med at mor og datter skal ha identisk posisjon.
SPM: Posisjonskvalitet. Ulike kvalietskrav på ulike prosesser.
SVAR: Vi har fått ny stedfestingsmetode der vi eksplisitt kan få presis lik stedfesting på mor og datter når vi ber om det.
SPM: Sjekke ut avstandsberegning – hvis vi bruker avstand til tyngdepukt for linjer og flater så får vi problemer når vi skal koble rekkverksende med rekkverk. SVAR: Vi dobbeltsjekker det, skal være enkelt å bytte ut med avstand til nærmeste punkt på linje.
Videre plan nye Datafangst:
- Jobber mer detaljert med designskisse, stedfesting, egenskaper m.m.
- Lager mer detaljert fremdriftsplan
- Arbeid i tabell
- Innsending til NVDB.
Demo NVDB rapporter og Datafangst 8. februar 2023
Gamle Datafangst:
Håndtere geometrifeil fra NVDB (medførte crash). Dette er rettet i den forstand at feilen ikke crasher Datafangst.
Datakatalog-justering: «Påkrevd, ikke absolutt» er nå døpt om til «påkrevd».
Nye Datafangst design og arbeidsflyt
Designere har fått mange verdifulle tilbakemeldinger om kronglete tilfeller. Sykdom har hindret brukerintervju, sender nye innkallinger. Arbeidsdeling Helene – Justyna. Lager oppgaver til utviklere (og designere!) i designverktøyet «figma», bedre struktur og flyt.
Utvikling nye Datafangst:
- Fokus på sammenkobling.
- Stedfesting og kobling – knapp for objekter som ikke finnes på kontrakt er byttet med «importer» – knapp.
- Sammenkoble-knapp. Bedre visning av sammenkoblede objekter
- Flyt «legg til relasjon» i arbeid, søker på objekter i nærheten. Viser avstand til aktuelle objekter.
Kart og databehandling.
- Søkekomponent, fjernet og ryddet slik at vi nå kun har én søkekomponent. Ryddet i koden (og i GUI)
- Vise ekstverdi for flerverdiattributter (enum-verdier).
- Statistikk – eget kartlag.
- Refaktorering / rydding
Kontraktløs: Kan skjule vegobjekttyper. Resetting av verdier i nedtrekksmeny deaktiveer ikke innsendingsknapp. Datofelt crasher ikke ved ugyldig dato. Lager API for «feature service». Lager API klienter i javascript (typescript) og java.
Demo
Sammenkobling: 1 skiltpunkt og 3 skiltplater importert på kontrakt (i samme punkt). Mer beskrivende navn på objekter kommer etter hvert (p.t. kun tilfeldig generert ID). Sammenkoblingsmodal blir ikke oppfrisket etter sammenkobling, og popup med «sammenkobling vellykket» er p.t. usynlig (dette kommer, vi jobber med løsning der vi bruker SVV designfarger)
Kontraktsløs:
Kan skjule objekttype fra kart. Dyplenke: Aktive og inaktive kartlag lagres til lenken i adressefeltet (som kan bokmerkes eller deles).
Planer videre:
- Ferdigstille sammenkobling
- Stedfesting
- Innsending til NVDB
Demo NVDB rapporter og Datafangst
Opptak fra møtet (mangler dessverre opptak fra første delen delen der vi snakker om arbeid utført på gamle datafangst)
Enkelte endringssett ble ikke vist som «utført» selv om de var det. Løsning: Hyppigere oppfriskning av status innsendte endringssett.
SPM: Problem med dobble filer (data blir lastet opp flere ganger).
SPM: Dele dokumentasjon på vegdata.no SVAR: Tar mål av oss til å lage brukerdokumentasjon parallelt med at vi bygger nye funksjoner. Da får vi også en del fine ekstragevinster ved at brukertesterne (referansegruppa) ikke bare tester ny funkjsonalitet: De tester også den nye dokumentasjonen og bidrar til å forbedre denne.
EDIT: Vi utvikler ny plattform for dokumentasjon av våre NVDB-løsninger, nye Datafangst vil komme inn der https://nvdb.atlas.vegvesen.no/
Demo
Endringer på enkeltobjekt.
Mye mer kompakt dialog for å endre enkeltobjekt. Denne dialogboksen vil nok bli redesignet i tråd med det designarbeidet som skal implementeres.
Jobber med visning og redigering av relasjoner.
SPM: Visning av objekter som ikke er koblet sammen (evt ikke skal kobles). Svar: Disse objektene vil vises som egne rader i dialogen, uten den linja som symboliserer relasjonen.
SPM: Må vise relasjon i kart. Svar: Vi så absolutt bli mulig å velge både mor og datter i kart.
SPM: Må kunne zoome veldig langt inn for å skille nærliggende objekter fra hverandre. Svar: Ingen praktisk begrensning på zoomlevel. At bakgrunnskartet ikke har så stor detaljgrad (blir kornete) vil ikke hindre deg i å zoome lengre inn, slik at du kan skille nærtliggende objekter fra hverandre.
SPM: Initiativ fra rådgivere og entreprenører om mulighet for å benytte IFC for NVDB-objekter. Noen her som har noen tanker/kommentarer? Svar: Dette spørsmålet er ikke relevant for denne demoen.
SPM: Lenke til nye datafangst. SVAR:
I produksjon: https://datafangst.atlas.vegvesen.no/
TESTPROD https://datafangst.test.atlas.vegvesen.no/
SPM: Oppfordres til å gjøre lenkene tilgjengelig på vegdata.no – SVAR: Notert.
LØST Vegkart mangler meterverdier og vegbilder, vi er på saken
EDIT kl 14:48: Tilgang til skjermede objekttyper fungerer igjen, vi har rullet tilbake til tidligere versjon av vegkart. Vi beklager ulempene for våre brukere
EDIT kl 13:37: Vegreferanse og vegbilde fungerer. Og vi skal straks rulle tilbake til versjon der tilgangen til skjermede objekttyper fungerer igjen
I nyeste versjon av vegkart så fungerer ikke popup med vegreferanse og lenke til vegbilder.
Vi har også problemer med å vise skjermede data
Utviklerne er på saken, mer info kommer fortløpende.
Sist oppdatert: Tirsdag 3.1.2023 kl 14:48
Demo NVDB rapporter og Datafangst 21.12.2022
Demo NVDB rapporter utgår pga sykdom
Dagens datafangst:
Disken gikk nesten helt full, vi fikk utvidet med mere diskplass før systemet crashet.
Enkelte endringssett ble ikke registrert som utført i DF. Noen få endringssett ble bare stående og «snurre» selv om de var utført i SKRIV. Dette gir følgefeil med mye lengre ventetid på andre endringssett, pt ca 15 minutt. Vi har laget en feilretting som løser problemet, men må teste litt mer før vi ruller ut i produksjon.
Nye DF
Kontraktsløs innsending: Klar til produksjonssetting, men venter til over juleferien.
- Enhet på egenskaper: Vi viser nå frem enhet på de egenskapsverdiene som skal ha dette i følge datakatalogen, slik som meter, antall, dato etc.
- Løst problem med at du ikke får skrevet desimaltall ved Kontraktsløs redigering
- Kan nå gjøre kontraktsløs korrigering av egenskapsverdier.
- Løst feil med at lestFraNVDB-verdi blir 1 time feil (som igjen medfører at man må vente en time før man kan sende korreksjon).
- Ferdig-indeksering blir plukke topp etter kontraktsløs innsending. Dvs at vi sjekker for statusen UTFØRT OG ETTERBEHANDLET i API SKRIV og oppdaterer objektet så snart objektet får denne statusen.
- Enkel og ikke dobbel underlinje på statuslink innsending kontraktsløst kart (denne lenken tar deg til API SKRIV kontrollpanel for endringssettet).
Databehandling
- Uthening av vegobjekter i kontrakt er kjappere.
- Bygg om panelstrukturen i kontraktkartet
- Implementere «Vis i kart»
- Hente objekter fra kontrakt
- Skjule typeliste ved behov (ikke helt ferdig ennå).
SPM: Databehandling og uthenting. Kan vi hente data basert på vegsystemreferanse? SVAR: Jobber med design for dette, men ikke ferdig til implementering ennå.
SPM: Hente ut data basert på datakatalog-kategorier: SVAR: Har oppgave på det i vår backlogg
Implementere sammenkobling
- Hoover (mouseover-boble) på element i relasjonsvindu.
- Vise relasjoner i kart-popup.
- Bruke datakatalog for å avgrense mulige sammenkoblinger
- Nytt endepunkt for å fjerne sammenkobling mellom objekter.
Implementere Kart
- Søkeresultater i kart
- Flytte senterpunkt kart
Diverse
- Sikkerhet: Usikker lagring av ID-token, tilgangskontroll SubmissionService. Dette var de to siste oppgavene som blokkerte produksjonssetting.
- Skru av nettleserens egen autocomplete i søkefelt for brukere i administrer kontrakt. (Var konflikt mellom nettleserens søkehistorie og DF sine autocomplete-forslag).
- Tekniske oppgaver med bedre systemlogging, organisering database, bugfiks.
Demo
Databehandling-fane, har søkt opp skiltpunkt og skiltplate. Klikk på samling (cluster) med vegobjekt, få opp relasjonstre og gå videre til «stedfesting og sammenkobling» – fanen.
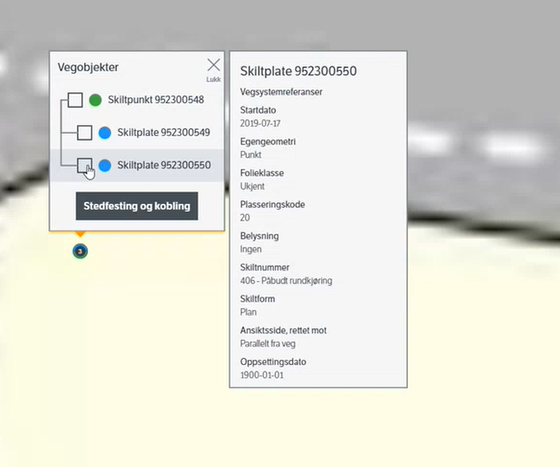
SPM: Få vist relasjoner i kart selv om objektene ikke ligger samme sted. Deaktivere autozoom ved behov? F.eks ved lange strekningsobjekt som har relasjon til punkt? (Tunnel, f.eks.). SVAR! Notert.Trolig gunstig med en knapp eller innstilling der du kan deaktivere autozoom.
SPM: Ønsker også bedre kontroll på objekt innafor og utafor et kontraktsområde.
SMP: Miljø: Utviklingsmiljø versus testprod (ATM) versus PROD: SVAR: Vi er konsistente på miljø: DF utv går mot NVDB API UTV, les og skriv, tilsvarende ATM (testprod) går mot NVDB api ATM LES+skriv.
Søkeresultat / autocomplete – bedre visning av autocomplete forslag ved søk.
Redigering av egenskap – når Datakatalogen definerer en enhet (meter, dato, antall, tidspunkt etc) så viser vi denne enheten.
Flyt registrering – etterbehandling. Fargekoder i statusfelt nederst.

SPM: Redigeringsboksen bør gjøres mer kompakt, store bokstaver og mye luft. SVAR: Enig, og vi har allerede en oppgave på å gjøre den mer kompakt.
Nytt design stedfesting og sammenkobling
Designerne viser de skissene som utviklerne skal jobbe etter når vi implemnterer stedfesting og sammenkobling. Disse skissene er blitt til gjennom ganske mange brukerintervju og brukertester, i flere itereasjoner. Skissene er p.t. fremdeles noe uferdig, vi jobber videre med å foredle informasjon fra brukertester og få dem inn i skisser etc, men det grunnleggende er på plass slik at utviklerne kan starte implementasjon.
Søkemulighet – blant objekter som finnes på kontrakt, og etter hvert valg for å søke blant alle NVDB-objekt. Ønsker også søkemulighet på vegsystemreferanse. Kan åpne innstillinger for å få fram disse mulighetene.
SPM: Ønsker egenskapsfilter på søk etter vegobjekt. SVAR: Enig, notert
Eksemplet viser tre objekttyper, kan være flere. Kan vise alle objekt, eller bare noen av dem. Velger objekter (med lasso, innafor kartutsnitt m.m.) Får tilgjengelig liste med valgte objekter. Kan velge vekk enkeltobjekter i denne listen.
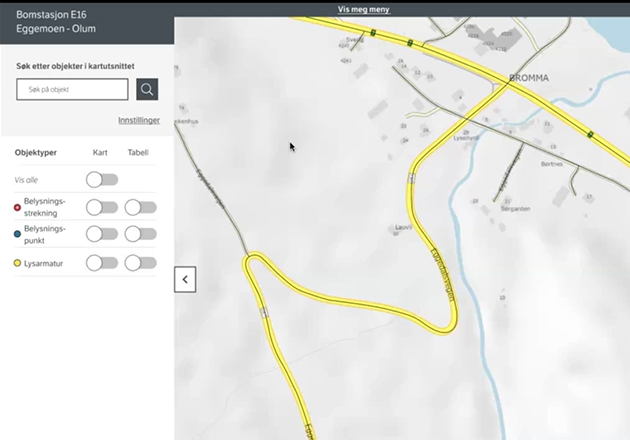
SPM: Ønsker mouseover-popup med info om egenskapsverdier når du holder musepeker over ett objekt i listen: SVAR, ja det kommer, men får ikke vist det i prototype-verktøyet.
Fra valgte objekt kan du velge om du først skal gjøre stedfesting eller sammenkobling (to faner i dialogvindu). Velger her å gjøre sammenkobling først. Kan granske evt relasjoner som finnes fra før, f.eks får fram hvis et bel.punkt har en lysarmatur. Kan velge bort et objekt fra listen.
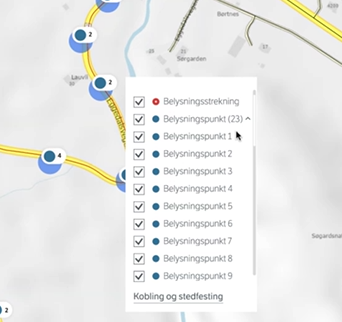
SPM: Hva med å «koble til ny mor» når man avdekker feil i eksisterende relasjoner? SVAR: God idé, notert!
Stedfesting: Forhåndsvalgt er «nærmeste veg». Kan velge en annen veg. Når fornøyd kan du klikke «stedfest». Hvis du velger å stedfeste mor-objekt så får du også spørsmål om du skal stedfeste de tilhørende datterobjekter samtidig. Kan velge vekk enkeltobjekter som krever særbehandling.
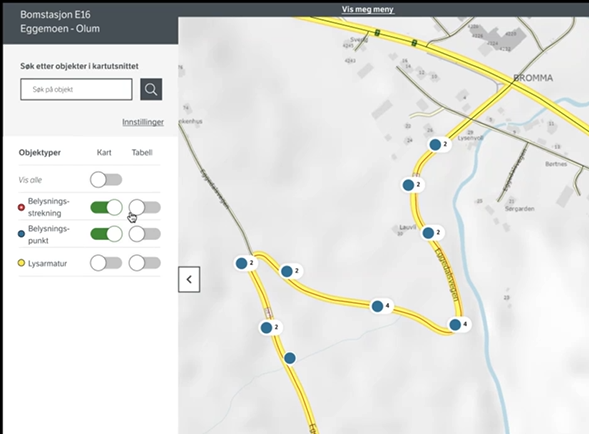
SPM: Hvordan velge andre veger enn nærmeste? SVAR: Jobber med funksjonalitet der vegnett er synlig og valgbart oppå objekttypene, slik at stedfestingen vil skje på det vegnettet du har valgt.
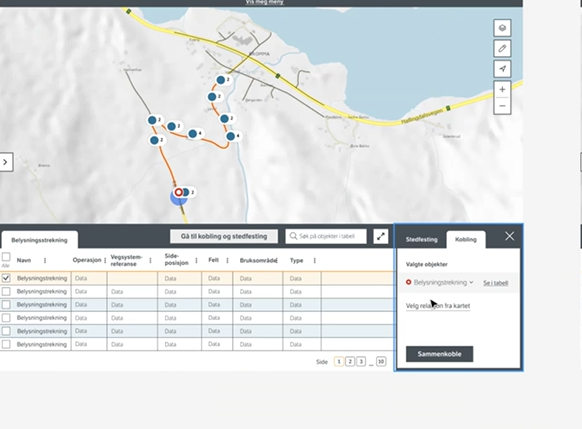
Kan også gjøre stedfesting og sammenkobling via tabell. Kan jobbe med ett og ett objekt av gangen når det er gunstig. Senere ønsker vi mer raffinerte søkemuligheter for å få bedre forslag til sammenkobling.
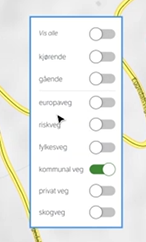
Vegnett: Tydelig ønske fra brukere at vegnettet er godt synlig når du åpner kartet. Et høyreklikk i kart får opp dialog der du kan velge trafikantgruppe og vegkategori.
Objekt ikon: Jobber med fargevalg og symboler, universell utforming. Visning av enkeltobjekt:
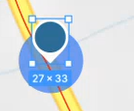
Visning av flere objekt som står såpass nær hverandre at vi må vise en klynge (cluster) av objekter:

Viser også om klyngen består av flere ulike objekttyper eller samme objekttype (dette kan du få hvis du velger å vise mer enn en objekttype av gangen i kartet)

EDIT – tilføyelse 22.12: Tegnforklaring, slik skiller vi mellom at objekter kan stå nært hverandre eller i samme posisjon – og om objektene er av samme eller ulik type:

SPM: Ønsker tydelig markering av start og slutt på strekningsobjekt. Spesielt viktig når du har flere strekningsobjekt nær hverandre. Svar: Enig, notert.
SPM: Vise skiltplater sammen med sideposisjon og retning (ansiktsside). NVDB 123 er (var) et bra forbilde. SVAR: Vi har ikke tenkt detaljert på det, men tar det selvsagt videre. Vi har symbolbibliotek for de enkleste skiltplatene, så dette bør vi få til. Kan vi vise skiltplate i tabell? Nei, må vises i kart, med ansiktsside orientert riktig ihht slik man ser skiltet langs vegen. Krever nok en del designarbeid for å bli bra.
SPM: Vise stedfesting med strek fra objekt til senterlinje. SVAR: Ja, dette ønsker vi å få til, men vi får ikke vist det i prototype-verktøyet.
Oppsummering:
Bra framdrift trass i noe sykdom. Velger å ikke produksjonssette «Kontraktsløs redigering» før jul.
Plan videre: Produksjonssetting, jobbe videre med design og gå fra skisser til implementering.