Vi har for tiden litt plunder med pålogging datafangst. Vi har funnet feilen, og regner med det blir løst raskt
Forfatterarkiv: jankristian
Gamle ÅDT-tall er satt historisk
Vi har nettopp sendt alle trafikkmengde-objekter med ÅDT, gjelder for lik 2019 eller eldre over i historien, dvs objektene er lukket og har fått en sluttdato. De vises ikke lenger i Vegkart, men de kan hentes fram fra NVDB api LES med oppskriftene beskrevet her: Hvordan får jeg historiske data for trafikkmengder?
Grunnen er at disse gamle ÅDT-verdiene skapte en del kluss, heft og problemer for analyser og bruk av trafikkmengde-data. Vi hadde også stor pågang på support med å forklare hvordan det hang sammen at vi hadde opp mot ti år gamle data liggende ved siden av 2020-data.
NVDB api LES fungerer ikke
6.12.2021 klokken 12:44 Vi FRISKMELDER NVDB api LES, i både PRODUKSJON og TESTPROD (ATM). Utviklingsmiljøet vårt har ikke hatt disse problemene
6.12.2021 klokken 12:30: Alt ser greit ut så langt, vi vurderer full friskmelding, men testing pågår ennå
6.12.2021 klokken 11:50: Vi har fått NVDB api LES igang igjen, har ikke rukket å teste alt grundig, men det ser OK ut så langt
Vi jobber med feilsøking, oppdaterer så snart vi har mer informasjon
Feilen påvirker alle systemer som bruker data fra NVDB api LES, deriblant Vegkart, NVDB rapporter, Datafangst med flere
Snublefeller, historiske data
Bruk av historiske data har en del interessante snublefeller og begrensninger
Sjekk også vår artikkel om hvordan du tar ut historiske data i ulike verktøy.
Vegsystemreferanse fantes ikke før november 2019
I november 2019 innførte vi det nye referansesystemet, populært kalt vegsystemreferanse. Sjekk artikkelen Hva må jeg vite om vegsystemreferanse? Denne er ikke gitt tilbakevirkende kraft, det vil si at hvis du tar ut de dataene som var gyldige i 2018 så får du ikke med detaljer om strekning, delstrekning, kryssdeler, trafikantgruppe og metrering. Spesielt interesserte kan skjøte på med info hentet fra historiske 532 Vegreferanse – objekter.
Men vi la på detaljer om vegnummer, fase og vegstatus på alle historiske objekter i NVDB api LES, så du kan søke på f.eks. Fv915 når du skal ta ut historiske data. Merk at data eldre enn 2019 har fått 2019-vegnummeret.
I NVDB bruker vi kun de nyeste kommunegrensene!
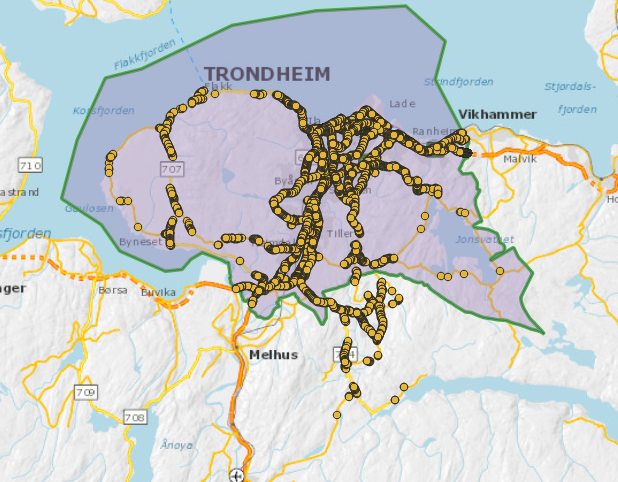
Endrer vi på kommune- og fylkesgrenser så får det tilbakevirkende kraft i NVDB. Du kan ikke lenger søke etter belysningspunkt i Klæbu, for Klæbu er en del av nye Trondheim kommune. Og motsatt – søker du etter historiske data for belysningspunkt så er det dagens kommunegrense som brukes som søkefilter. Kartskissen under viser 2017-grensene for Trondheim samt de belysningspunktene du får når du søker på belysningspunkt med filteret tidspunkt=2017-02-01&kommune=5001
I NVDB bruker vi kun de nyeste kontraktsområdene – og liker best det nyeste vegnettet
Hvis du henter ut historiske data for et kontraktsområde og enten vegnettet eller kontraktsområdet (eller begge deler!) har vært endret så må vi ta forbehold om at du kan få færre vegobjekter enn det riktige.
Hvis du vet at vegnettet og ditt kontraktsområde har ligget i ro i tiden mellom i dag og bakover til det eldste tidspunkt du trenger data for – så kan du helt fint ta ut historiske data på dette kontraktsområdet.
Forklaringen er komplisert: Når kontraktsomrdet skal brukes som søkefilter i NVDB api les så klarer vi ikke gjenskape området slik det så ut før endringen, men bruker området slik det ser ut i dag – også for historiske søk.
Hvis en bit av vegnettet var i k.området i 2019, men ble satt historisk i 2020 – så vil du ikke klare finne den når du søker på k.området i dag med tidspunkt=2019.
Tilsvarende hvis k.området har vært justert i 2020: Du klarer ikke få frem riktige 2019-data ved å bruke k.området som søkefilter.
Det finnes krokveier om dette problemet, men det er komplekst (hent ut historisk 538-objekt per tidspunkt, finn dette objektet stedfesting og hent ut vegobjekter som hadde overlappende stedfesting på det tidspunktet.) Vi ønsker å tilby ferdige rapporter basert på denne logikken, men det ligger noe fram i tid.
Hvordan får jeg historiske data for trafikkmengder?
Her er oppskrift på hvordan du kan ta ut historiske data for trafikkmengder i ulike verktøy. I prinsippet er enkelt – du føyer til parameteren tidspunkt=VALGT DATO i spørringen til NVDB api LES – i tillegg til andre søkeparametre (som f.eks kartutsnitt m.m). Alle spørreparametrene er beskrevet i dokumentasjonen for NVDB api LES.
For å få all tidsutvikling i samme spørring kan du i stedet for tidspunkt bruke parameteren
alle_versjoner=true(for vegobjekter). Resultatet blir litt mer uhåndterlig spagetti med absolutt alle historiske og nåværende data fra NVDB, og krever gjerne litt sortering, filtrering og gruppering før man får struktur på dataene. For vegnett heter denne parameterenhistorisk=true.Sjekk også vår artikkel om Snublefeller, historiske data
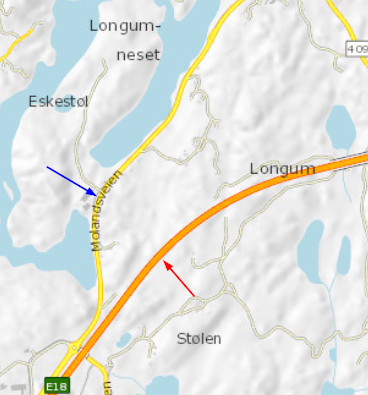
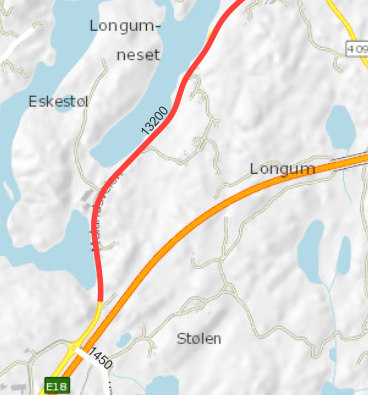
Nedenfor viser vi eksempel på gamle og nye data for biter av gammel og ny E18-trasé ved Arendal. Den nye motorveien Arendal-Tvedestrand åpnet juli 2019, og trafikkmengden på gammel E18-trasé (nåværende Fv421) har gått ned med om lag 10.000 kjøretøy per døgn.
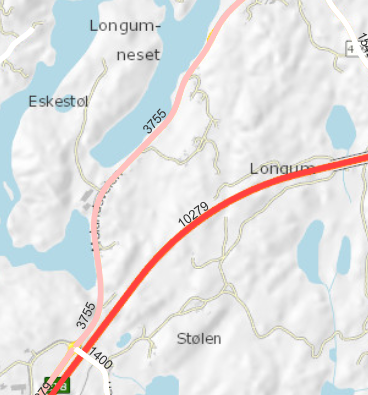
EDIT: Vegkart støtter nå historiske data
Våren 2022 satte vi i produksjon vegkart med støtte for historiske søk. De historiske søkene er fremdeles tregere enn standardsøkene, men det er etter vårt syn til å leve med.
Vi har laget ferdig en vegkart-versjon der du kan søke etter historiske data, men det gikk for tregt til at vi kunne produksjonssette den. Vi opplevde kanskje 20-30 sekunders ventetid før vegkartspørringen etter historiske data ga respons – og dette er helt uaktuelt å tilby brukere av en moderne webløsning i 2021. Historiske søk kommer nok til vegkart, men vi trenger mer tid før det blir bra nok.
Vegkart eksport – SOSI og CSV
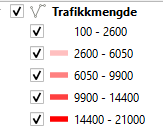
Her er et tjuvtricks som bruker CSV- og SOSI eksport for å laste ned historiske data – det fungerer, selv om vegkart ikke innbyr til det. Gjør et vegkart-søk og kopier nedlastingslenken fra søket ditt (ekspander treffboksen og høyreklikk over det klikkbare feltet CSV eller Sosi for å få tilbud om å kopiere lenken). Denne lenken limer du inn i en teksteditor og føyer til valgt dato på formen &tidspunkt=2021-03-15 Merk at spørreparametrene skal være adskilt med ampersand (& – tegnet).
Denne modifiserte lenken kan du så lime inn i nettleserens adressefelt + ENTER. Nedlastingen skal nå starte automatisk.
&tidspunkt=2021-03-15 FME
Eksempel workspace for nedlasting av historiske trafikkmengde finner du her https://github.com/LtGlahn/nvdbapi-v3-FME
Argcis Pro
Firmaet Geodata A/S tilbyr en geoprosesseringstjenste hvor man asynkront kan laste ned data fra NVDB. Data blir pakket om til en esri-vennlig datastruktur på fil-geodatabase format, og når det er ferdig får du epost med lenke til nedlasting. Menyvalg for område, objekttyper, egenskapsverdier og andre typer filter blir bygget dynamisk i arcgis pro når du kobler deg til. De fleste (og viktigste) filtreringsmulighetene er støttet, men ikke alle. For eksempel tilbys menyvalget tidspunkt=DATO, men ikke historisk=true.
Qgis 3
Vi har laget et python-bibliotek hvor du bruker python konsoll for å laste ned data fra NVDB api LES direkte til kartflaten i QGIS 3, det finner du her. Følg oppskriften for nedlasting og kjør scriptet qgis3script-importernvdbdata.py med dine lokale tilpasninger, slik at biblioteket blir riktig importert til python konsollet. Deretter er du klar til å laste inn data med kommandoene
traf = nvdbFagdata( 540 )
traf.filter( { 'kommune' : 4203, 'tidspunkt' : '2019-04-01' } )
nvdbsok2qgis( traf )
NVDB rapporter
Naviger til og velg egendefinerte rapporter. Menyen for å velge objekttyper er todelt: I den venstre menyen søker du etter Trafikkmengde og huker av. Bruk pilene for å flytte markerte objekttyper over til høyre meny – som er de objekttypene som kommer med i rapporten.
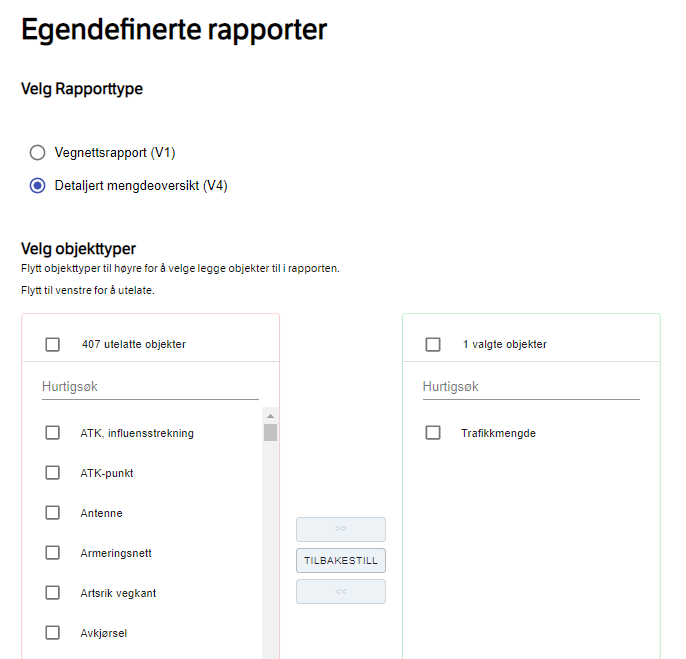
Scroll lenger ned for å velge område. For dataene i vårt eksempel har vi brukt valgene kommune = Arendal og tidspunkt = 2019-04-01
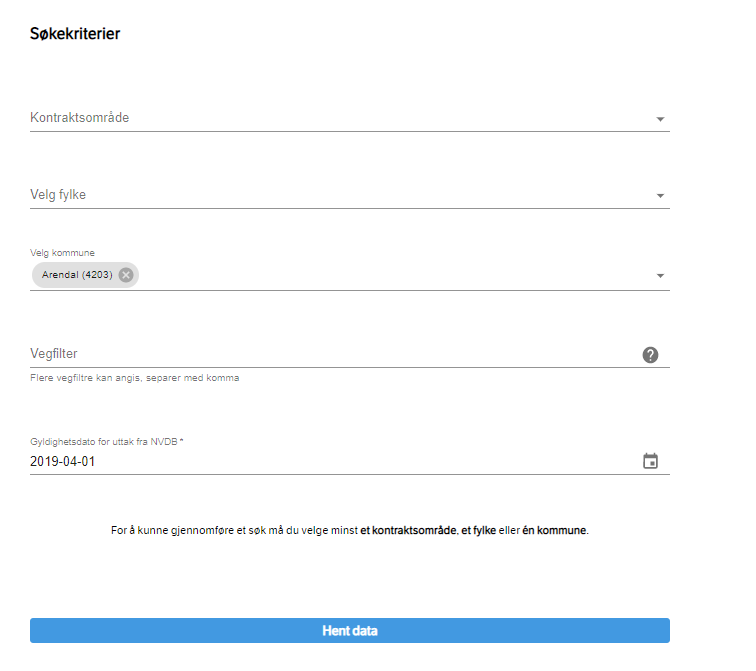
Den ferdige rapporten får litt begrenset bruksverdi når vi henter data som er eldre enn vegreferansesystemet som ble innført november 2019. I den ferdige tabellen er det derfor kun fyllt ut data for vegnummer, ikke strekning, delstrekning og meter – og dermed er det litt tungvint å vite hvilke rader som er hvor på vegnettet.
Python
Den mest elegante metoden er å bruke det fulle GIS-arsenalet blant annet geopandas, men ikke alle trenger dette – og installasjonen kan være litt fiklete. Derfor har vi skilt lesing fra NVDB (som funker rett ut av boksen i plain python) fra de avanserte GIS-bibliotekene (som kan være litt plundrete å installere rett). Starter du fra scratch med python så anbefaler vi Anaconda-distrubusjonen, og så fortsette med bruke conda-systemet for pakkehåndtering og bruke conda til å lage et separat python-miljø (detaljert oppskrift).
Selve nedlastingen gjør du med dette python-biblioteket som du laster ned https://github.com/LtGlahn/nvdbapi-V3, og last ned data med kommandoene
sys.path.append( 'Sti til der du har repos https://github.com/LtGlahn/nvdbapi-V3' )
import nvdbapiv3 # reposet https://github.com/LtGlahn/nvdbapi-V3
traf = nvdbapiv3.nvdbFagdata( 540 )
traf.filter( { 'kommune' : 4203, 'tidspunkt' : '2019-04-01' } )
myList = traf.to_records() Nå har du data i minnet som en liste med json-dictionaries, og det kan jo knas videre i alle retninger.
En mulighet hvis du har pandas, geopandas og shapely-biblioteket installert kan du for eksempel lagre det som kartlag til harddisken din. Her går vi omveien om en såkalt dataframe til en geodataframe, som igjen har funksjoner for å lagre til et knippe geografiske formater – for eksempel det suverene filformatet geopackage
import pandas as pd
import geopandas as gpd
from shapely import wkt
mydf = pd.DataFrame( myList )
mydf['geometry'] = mydf['geometri'].apply( lambda x : wkt.loads(x) )
mydf.drop( 'geometri', 1, inplace=True )
myGdf = gpd.GeoDataFrame( mydf, geometry='geometry', crs=5973 )
myGdf.to_file( 'trafikkmengde.gpkg', layer='trafikkmengde2019-04-01', driver='GPKG' )
Datadump, eldre data
I 2020 og 2016 laget vi datadump med alle (datitdens) gyldige og historiske trafikkmengde-data. Ved siden av la vi også en dump av objekttypen 532 Vegreferanse, slik at man hadde mulighet til å se hvilke vegnummer som var gyldige til ulike tider på en bestemt strekning.
Info om datadumpen finner du her (vegdata-artikkel fra 2016, oppdatert med 2019-data. Når jeg sier 2019-data er det dette de ÅDT-verdiene som var tilgjengelig i 2019, dvs med År, gjelder for = 2018.
Sinus infra
I Sinus Infra kan du ta ut historiske data som var gyldige på en bestemt dato. Søk fram Trafikkmengde og trykk på områdefilter:
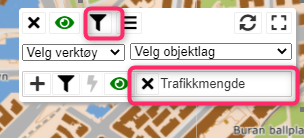
Velg Historisk og sett ønsket dato. Angi geografisk område (kommuner, fylker, kartutsnitt, eller som vist her – søkeradius i meter).
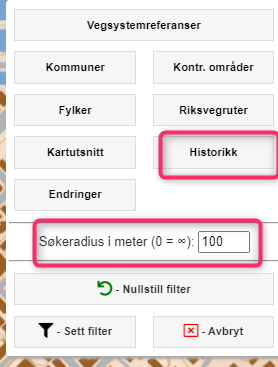
Angi søkedato som skal brukes:
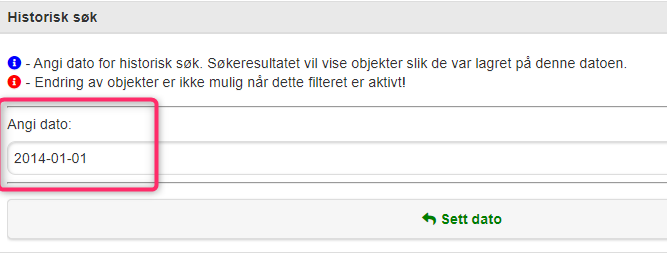
Søk etter historiske data
Det vi trenger er en oversikt for hva som er nytt per år. Altså hvis en veg får flere gatelys, fortau osv.
Dette er et behov som mange vegeiere og -driftspersonale har. Akkurat denne gangen kom spørsmålet fra Trondheim kommune, men det samme behovet har fylkeskommunene, entreprenører, Nye Veier A/S og Statens Vegvesen.
Vår anbefaling: Ta differansen mellom to datasett for ulike tidspunkt
NVDB api LES støtter datauttak på angitt tidspunkt (dato), med et par forbehold om at det ikke har vært gjort endringer på områdegrenser fra det første tidspunktet til i dag. Her er status på historisk søk i ulike verktøy per oktober-2019:
- NVDB rapporter, alle rapporttyper støtter datauttak på angitt tidspunkt. I denne sammenheng er det driftskontrakt-rapportene som er mest relevant.
- De fleste metodene for datauttak beskrevet her: Hvordan får jeg NVDB-data inn i kartsystemet mitt?
- Vi har testet historiske søk i Vegkart. Det fungerte, men ytelsen var ikke bra nok. Vi jobber med saken!
Vi har noen forbehold! Hvis det har vært gjort justeringer på kontraktsområder og/eller vegnett kan du få litt … lite intuitive resultater, se under. I tillegg får du litt merarbeid om du ønsker å sammenligne data før og etter en kommunesammenslåing.
NVDB bruker kun de nyeste kommunegrensene!
I NVDB bruker vi kun ferske data for fylker og kommuner – med tilbakevirkende kraft. Så i 2021 finner du for eksempel ingen spor etter gamle Klæbu kommune.
Dette betyr at når du søker etter belysningspunkt i Trondheim for en tidligere dato, for eksempel 1. februar 2017, så får du treff på dagens Trondheim kommune. Mer presist 10625 objekter, hvorav 927 er i gamle Klæbu kommune.
Selve søket mot NVDB api ser slik ut:
https://nvdbapiles-v3.atlas.vegvesen.no/vegobjekter/87?kommune=5001&tidspunkt=2019-02-01&inkluder=alleMen hva med endret – funksjonen i NVDB api? Hvorfor ikke bruke den?
NVDB api LES tilbyr parameteren endret_etter, og den har sin anvendelse – men for akkurat dette behovet blir det for mange snublefeller. Resultatene fra denne spørringen:
https://nvdbapiles-v3.atlas.vegvesen.no/vegobjekter/87?kommune=5001&endret_etter=2021-09-22T00:00:00 må suppleres med en hel del datamassasje: Du må skille endret fra nye objekter, evt om det er nye versjoner av gamle objekt – og du må sjekke om noen objekter kan være slettet. Etter vårt syn er det bedre å ta differansen mellom to ulike datoer.
Historiske data per Kontraktsområde – brukes på egen risiko
Hvis du henter ut historiske data for et kontraktsområde og enten vegnettet eller kontraktsområdet (eller begge deler!) har vært endret så må vi ta forbehold om at du kan få færre vegobjekter enn det riktige.
Hvis du vet at vegnettet og ditt kontraktsområde har ligget i ro i tiden mellom i dag og bakover til det eldste tidspunkt du trenger data for – så kan du helt fint ta ut historiske data på dette kontraktsområdet.
Forklaringen er komplisert: Når kontraktsomrdet skal brukes som søkefilter i NVDB api les så klarer vi ikke gjenskape området slik det så ut før endringen, men bruker området slik det ser ut i dag – også for historiske søk.
Hvis en bit av vegnettet var i k.området i 2019, men ble satt historisk i 2020 – så vil du ikke klare finne den når du søker på k.området i dag med tidspunkt=2019.
Tilsvarende hvis k.området har vært justert i 2020: Du klarer ikke få frem riktige 2019-data ved å bruke k.området som søkefilter.
Det finnes krokveier om dette problemet, men det er komplekst (hent ut historisk 538-objekt per tidspunkt, finn dette objektet stedfesting og hent ut vegobjekter som hadde overlappende stedfesting på det tidspunktet.) Vi ønsker å tilby ferdige rapporter basert på denne logikken, men det ligger noe fram i tid.
Hvor mangler vi kontraktsområde?
Fra våre venner hos fylkeskommunen fikk vi denne utfordringen:
Det fylkeskommunen ønsker, er å finne ut om det er noen deler av fylkesvegnettet som ikke har knyttet et kontraktsområde til seg. Slik det er i dag, må man sammenligne to rapporter og finne forskjellen
Dette er et flott eksempel på noe som ikke er ferdig støttet i våre produksjons- og rapporteringsystemer, men som fint lar seg løse med ørlite grann koding, for eksempel i FME eller python.
Kontraktsområder er såpass viktige at vi i NVDB api segmenterer alle andre data med informasjon hentet fra objekttype 580 kontraktsområde. Dermed kan du bruke navnet på kontraktsområde som søkefilter i Vegkart og NVDB api. I vegkart-veiledningen har vi et eksempel på hvordan du kan vise vegnettet for et kontraktsområde i Vegkart.
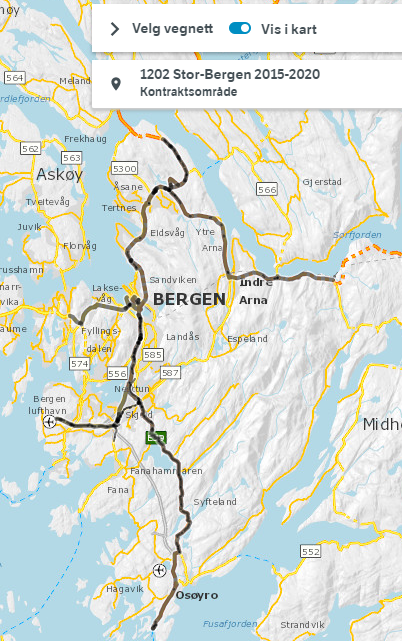
Men hvordan finner vi det vegnettet som mangler kontraktsområde?
Ta en litt grundigere titt på en bit av segmentert vegnett: https://nvdbapiles-v3.atlas.vegvesen.no/vegnett/veglenkesekvenser/segmentert/804767 . På JSON-format ser det noenlunde slik ut (forkortet for lesbarhet):
{
"href": "https://nvdbapiles-v3.atlas.vegvesen.no/vegnett/veglenkesekvenser/segmentert/804767",
8< --- forkortet for lesbarhet
"kontraktsområder": [
{
"id": 1013305686,
"nummer": 9304,
"navn": "9304 Bergen 2021-2026"
},
{
"id": 1010943925,
"nummer": 1202,
"navn": "1202 Stor-Bergen 2020-2021"
}
]
8< ---- forkortet for lesbarhet
}For hvert eneste vegsegment har vi altså en liste med de kontraktsområdene som gjelder for dette vegsegmentet. Hvis det ikke er registrert noe kontraktsområde for et segment så er denne listen enten tom (for JSON-formatet) eller mangler (XML-formatet). For eksempel https://nvdbapiles-v3.atlas.vegvesen.no/vegnett/veglenkesekvenser/segmentert/2720672
{
"href": "https://nvdbapiles-v3.atlas.vegvesen.no/vegnett/veglenkesekvenser/segmentert/2720672",
8< --- forkortet for lesbarhet
"kontraktsområder": [],
8< --- forkortet for lesbarhet
}Løsningen for å finne veger uten kontraktsområde blir da å lage litt kode som henter data fra NVDB api:
- Les deg opp på artikkelen Hvordan får jeg NVDB-data inn i kartsystemet mitt? | Vegdata.no
- Lag et filter søket ditt til det vegnettet du er interessert i. Eksempel fylkesveger i Innlandet så føyer du til parametrene vegsystemreferanse=Fv&fylke=34
- Last ned segmentert vegnett med det filteret du laget, eksempel https://nvdbapiles-v3.atlas.vegvesen.no/vegnett/veglenkesekvenser/segmentert?vegsystemreferanse=Fv&fylke=34
- Løp gjennom alle vegsegmentene og ta vare på dem som mangler data for kontraktsområder.
Har du kodeeksempler?
Klart det – her er et enkelt python kodeeksempel
Et mer komplett python-kodeeksemplet gjør bruk av Pandas Dataframes og Geopandas Geodataframes, samt mitt eget python-bibliotek for å lese data fra NVDB api. Installasjon av disse komponentene kan gi høy brukerterskel for uøvde brukere.
Vi kan helt sikkert lage et FME-kodeeksempel hvis det er interessant.
Hvordan vise skjermede data
Visning av skjerma data i Vegkart er det mange som etterlyser, men dette ligger nok et stykke frem i tid. Derfor må vi utforske andre løsninger.
Suverent enklest: Bruk QGIS
Innstaller QGIS, og følg oppskriften her for å installere pythonkode for å lese data fra NVDB via pythonkonsollet i QGIS. Deretter er det kun et par linjer for f.eks. å lese ut Vegros-data for Innlandet kommune
vegros=nvdbFagdata(895)
vegros.filter( { 'fylke' : 34, 'vegsystemreferanse' : 'Fv' } )
vegros.forbindelse.login( username='jajens', miljo='prodles', pw='***' )
nvdbsok2qgis( vegros)
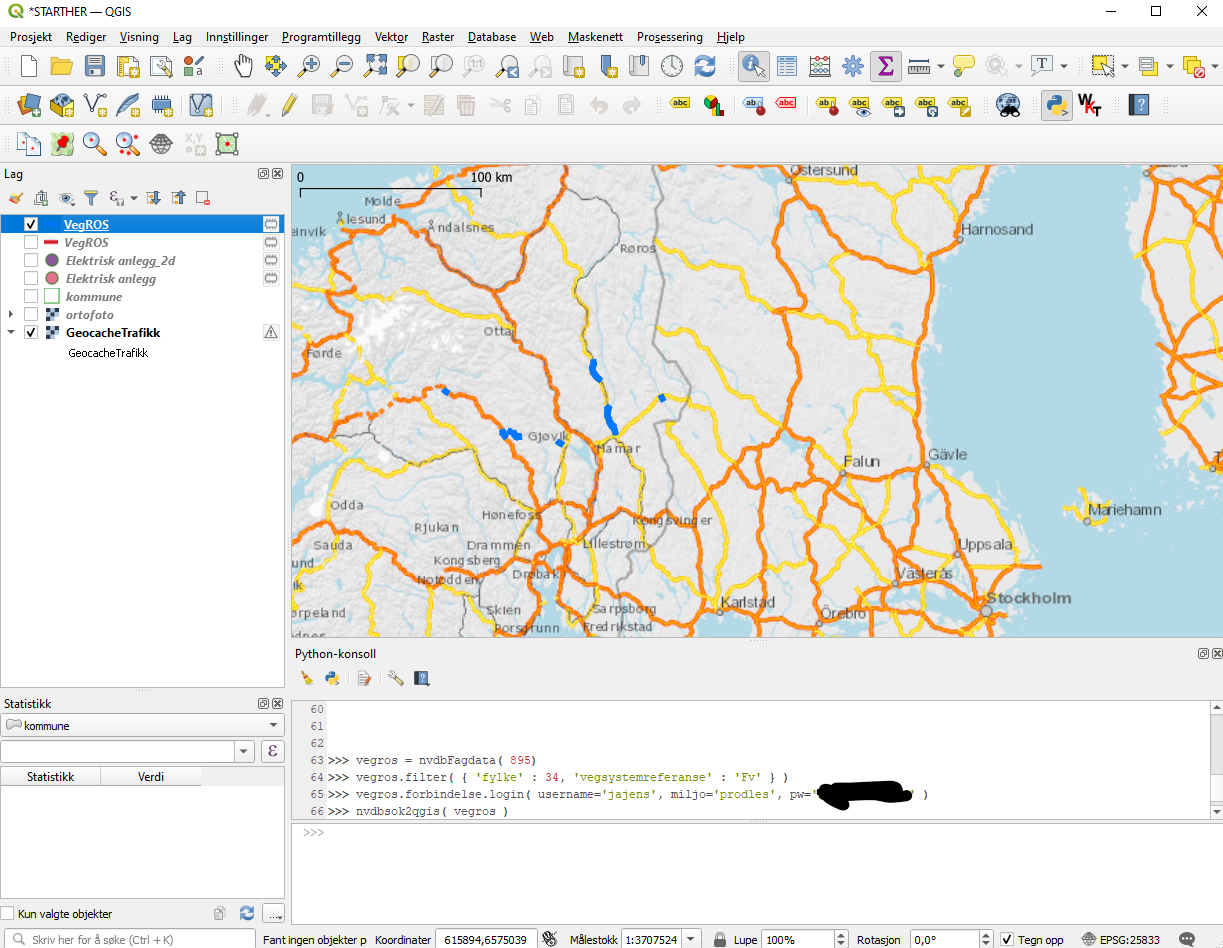
Når data er inne i QGIS kan man lagre til populære og moderne kartformater, eller eksportere til for eksempel Excel.
Alternativ løsning: Python, FME eller din egen løsning
De samme python-funksjonene som QGIS bruker er selvsagt tilgjengelig for en python-installasjon som står alene. (Vår anbefaling: Installer python distribusjon fra anaconda ). Vår anbefalte arbeidsflyt er å lese data inn i Pandas Dataframe, og eventuelt gjøre om denne til en GeoDataFrame. Derfra har du mange eksportmuligheter. I tillegg er (geo)dataframes i seg selv veldig kraftige analyseverktøy.
Akkurat i dag (14.04.2021) har vi ingen ferdige FME-workspace der påloggingsritualene er implementert, men det vil være en smal sak å implementere.
De samme påloggingsritualene kan du som utvikler også implementere i ditt favoritt programmeringsspråk. Enten for å lage din egen eksportrutine, eller for integrasjon i ditt favorittsystem.
Betingelser – hvilke rettigheter må man ha?
Tilgang til skjerma data i NVDB reguleres to – 2 – steder. (Jada, det er ett for mye, og vi jobber med det):
- Du må ha definert riktige roller og tilganger i NVDB databasen
- NVDB api LES har et eget system for hvilke skjerma data som blir tilgjengelig når du logger inn.
Rettighetene disse to stedene (NVDB databasen og i NVDB api LES) må selvsagt stemme overens.
Utfasing av gamle NVDB-systemer
Som konsekvens av kommune- og regionreformen har det vært nødvendig å gjøre større grep i og rundt NVDB. Samtidig har vi også benyttet sjansen til å modernisere og fase ut løsninger som i nær framtid uansett måtte erstattes. Endringene omfatter vegreferansesystem, vegnettsmodell, programmeringsgrensesnitt (API) og verktøy/klienter rundt NVDB. Dette arbeidet har pågått over flere år. I “anleggsperioden” har vi kjørt parallelle løp der både eksisterende og nye løsninger har vært tilgjengelig. Nå nærmer det seg tidspunkt for å fase helt ut de løsningene som ikke skal videreføres.
Planen er som følger:
1. juni 2021: Nedstenging av «NVDB Klassisk» – verktøy for alle som ikke spesifikt ber om tilgang fram til 1.8. Alle «NVDB Klassisk» – brukere kontaktes direkte via epost.
NVDB klassisk omfatter verktøy som NVDB 123, Funkra, NVDB studio, Vegreg og noen flere.
1. august 2021: Full nedstenging av gamle systemer. Det gamle api’et fases fullstendig ut, og de gamle verktøyene kan ikke lengre brukes mot NVDB.
I dette notatet er det beskrevet mer i detalj hva som videreføres og hva som ikke lenger blir tilgjengelig for vegnett, programmeringsgrensesnitt og NVDB-verktøy / NVDB-klienter.
Ruteplandatasett fra geonorge
Det er visst litt i overkant kronglete å pakke ut ruteplan-datasettet lastet ned fra geonorge på esri fil-geodatabase (FGDB) formatHer er par tricks som gjør livet enklere.
ALLER FØRST: Vis filtype (fil-etternavn) når du jobber skal håndtere dette datasettet! Standard i windows er å skjule filtypene. Det er sikkert fint i andre sammenhenger, men her skaper det problemer.
- Det du laster ned fra geonorge er en zip-fil med fil-etternavnet .zip, for eksempel Samferdsel_0000_Norge_25833_NVDBRuteplanNettverksdatasett_FGDB.zip
- En Esri fil-geodatabase er ei mappe (katalog) som inneholder .gdb i navnet – altså et fil-etternavn (.gdb) på ei mappe, for eksempel Samferdsel_0000_Norge_25833_NVDBRuteplanNettverksdatasett_FGDB.gdb
- Etter å ha «pakket ut» zip-fila så vil du ha en fil og en mappe med samme navn (f.eks Samferdsel_0000_Norge_25833_NVDBRuteplanNettverksdatasett_FGDB), kun fil-etternavnet skiller dem (.zip eller .gdb)
- Hvis du ikke har aktivert visning av filtyper (fil-etternavn) så har du ingen som helst mulighet til å skille zip-fil fra FGDB-mappen.
I filutforskeren viser du filtype ved å velge «Visning» og huke av for «Filtyper»

Derifra og ut er det vanlig utpakking av zip-fil, men med større kontroll.
I siste datasett (Samferdsel_0000_Norge_25833_NVDBRuteplanNettverksdatasett_FGDB) ser vi at mappen mangler fil-etternavnet .gdb. Dette er enkelt å fikse: Bare døp om mappen og føy til .gdb på slutten av filnavnet. Vi skal prøve å sikre at det blir riktig fil-etternavn på neste nettverksdatasett.